The perpendicular distance from a linear decision boundary to the closest training example. Maximising it is the defining principle of Support Vector Machines.
Definition
For a linear classifier and training set , the margin is:
In words: of all the training points, how far is the closest one from the boundary ? That distance is the margin.
The factor converts the algebraic value into a geometric distance. The same hyperplane can be described by infinitely many pairs related by a positive scalar; the norm in the denominator removes that ambiguity.
Distance From a Point to a Hyperplane
The perpendicular distance from any point to the hyperplane is:
Why in the denominator? is normal to the hyperplane (it points in the direction of steepest increase of ). The unit normal is . The signed distance from any point to the hyperplane along the normal direction is ; the absolute value drops the sign.

Why Maximise the Margin?
Suppose two hyperplanes both achieve zero training error. The one running through the middle of the gap between classes is more robust than one that just barely separates them:
- Robustness to noise. If a training point’s position is uncertain (measurement noise, label noise), a wide margin makes it less likely that the point — or any new point in its neighbourhood — ends up on the wrong side of the boundary.
- Generalisation. Loosely, a wide margin reflects strong evidence that the classes really are separated by this gap. There is a formal version of this intuition in VC-theory and PAC-Bayes bounds: roughly, classifiers with larger margins on the training data have provably tighter generalisation guarantees.
The classifier that maximises the margin among all hyperplanes correctly classifying the training data is the maximum-margin classifier, also known as the (hard-margin) Support Vector Machine.
Support Vectors
The training points that attain the minimum in — the ones sitting on the margin’s edge — are the support vectors. They alone determine the optimal hyperplane: removing any non-support-vector and re-fitting gives the same boundary.
This is striking. For a typical SVM trained on thousands of points, only a handful end up as support vectors. The rest sit comfortably on their side of the boundary and contribute nothing to the optimum. SVMs achieve a kind of structural data efficiency: they identify, automatically, which training examples actually pin the decision down.
The Optimisation
The natural formulation is a nested max-min:
(Here and means correct classification, so we can drop the absolute value.)
This nested form is awkward to solve directly, but it admits a clever canonical rescaling: since and describe the same hyperplane, we can set the scale so that the closest training point has . Under this rescaling the problem becomes:
The width of the resulting margin is — so minimising maximises the margin. See support-vector-machine for the full derivation.
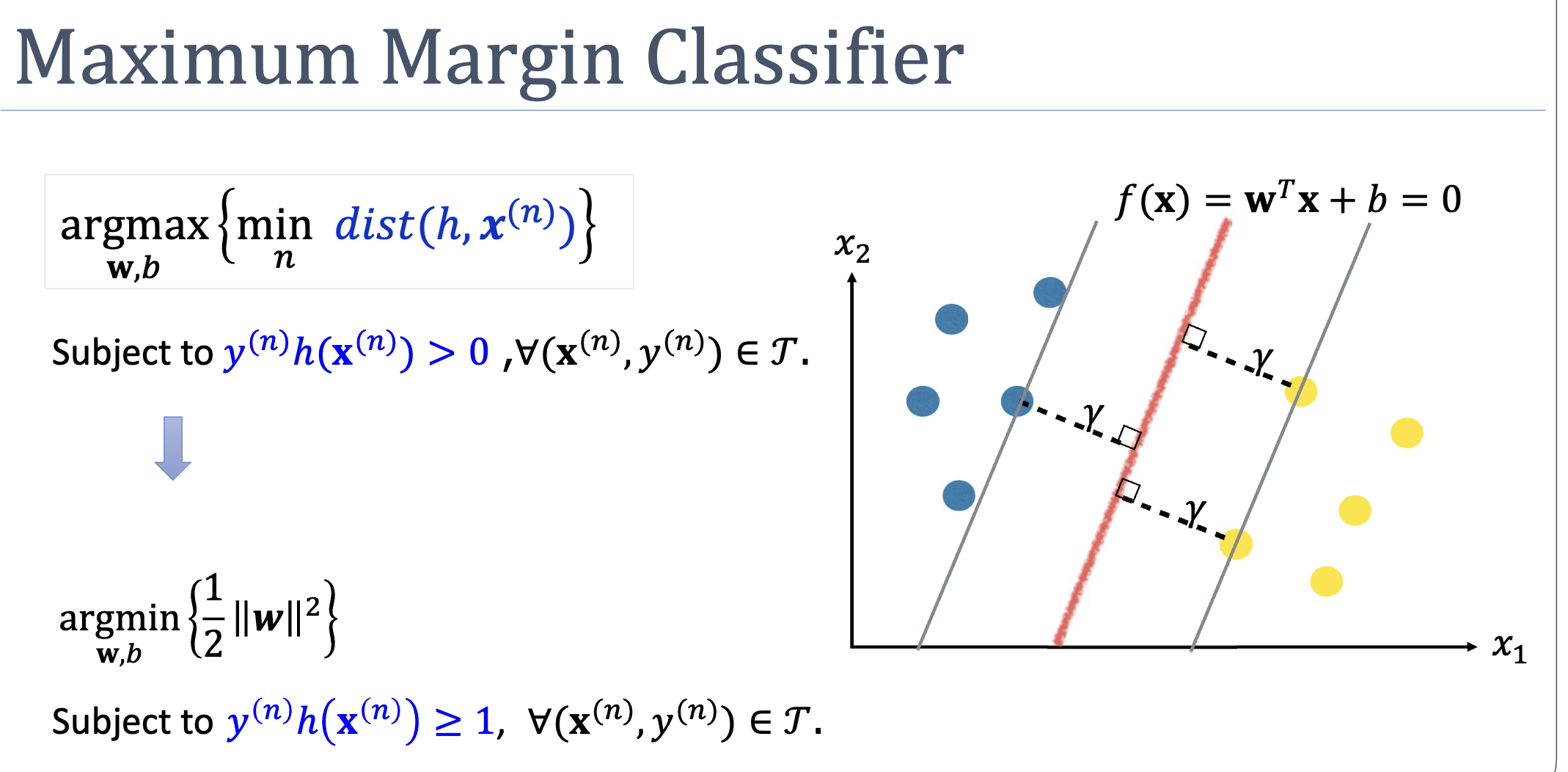
A Conventional Subtlety
The “margin” is sometimes defined as the width of the corridor — the distance between the two parallel hyperplanes and that touch the support vectors on each side. That width is . This module uses “margin” to mean the per-side perpendicular distance — so the corridor width is twice the margin. Either convention is fine as long as you’re consistent.
Related
- support-vector-machine — the algorithm that finds the maximum-margin hyperplane
- decision boundary — the hyperplane whose margin we measure
- generalization — wider margins correlate with better generalisation
- quadratic-programming — the convex optimisation form the maximum-margin problem reduces to
Active Recall
Compute the perpendicular distance from the point to the hyperplane .
. . Distance .
A maximum-margin classifier has been trained on 1000 points, of which only 5 are support vectors. If we delete one of the 995 non-support-vector points and retrain, what happens to the decision boundary, and why?
Nothing changes — the boundary is identical. Non-support-vectors satisfy strictly (they sit beyond the margin’s envelope), so they don’t enter the active constraint set of the optimisation. Removing them changes neither the objective nor the binding constraints, so the optimum is unchanged. This is why support vectors are the “critical” elements of the training set — they’re the only ones the boundary actually depends on.
Why does the formula for distance from a point to a hyperplane have in the denominator?
is normal to the hyperplane. The unit normal is . The signed distance from a point to the hyperplane along the normal direction is the projection of (any point on the plane) onto the unit normal, which works out to . The denominator normalises away the fact that the same hyperplane can be represented by infinitely many algebraically distinct pairs that differ by a scalar.