A finite polynomial that locally approximates a smooth function around a chosen point. The Taylor polynomial of degree matches the function’s value and first derivatives at that point, making it useful for analytical and numerical reasoning about local behaviour.
Why Polynomials?
Taylor approximation has a supremely practical goal: take a complicated, non-polynomial function like or and replace it locally with a polynomial that behaves the same way.
Why polynomials? Because they are the friendliest tools we have. Polynomials are easy to compute (just additions and multiplications), easy to differentiate, and easy to integrate. Replacing a hard function with a polynomial that matches it near a chosen point turns intractable analysis into algebra.
The fundamental intuition: you translate derivative information at a single point into approximation information around that point. Every twist of the function at the centre — its value, slope, curvature, rate of change of curvature, and so on — is encoded into a single coefficient of the polynomial. Match enough derivatives and the polynomial mimics the function.
Definition
The Taylor polynomial of degree of a function around the point is:
where is the -th derivative of evaluated at .
Expanding the first few terms:
The infinite series (taking ) is the Taylor series; for analytic functions it equals exactly within some radius of convergence.
Coefficients as Independent Derivative Controls
Forget the formula for a moment and write a generic polynomial centred at :
The coefficients are free parameters — we get to choose them. The Taylor expansion picks each one so that it controls exactly one derivative of at , independently of all the others:
- controls the value at . Plug into and every term vanishes, leaving . To match the function, set .
- controls the first derivative (slope) at . Differentiate once: . Plug in and only survives: . Set .
- controls the second derivative (curvature) at . Differentiate twice: . At , only contributes: .
- generally controls the -th derivative at .
The independence is the magic: when you take derivatives and evaluate at , every term of degree higher than still contains an factor and vanishes. So matching the -th derivative locks in alone, without disturbing any other coefficient. We can build the approximation derivative-by-derivative.
Why the ?
The factorial in the denominator is the price of the power rule. Watch what happens to as you differentiate it repeatedly:
| Step | Result |
|---|---|
| First derivative | |
| Second | |
| Third | |
| Fourth |
Each differentiation peels off a power and multiplies in a new integer. After derivatives of you are left with — a constant. So , not just .
To make equal , we have to divide out the that the power rule manufactures:
The factorial isn’t decoration — it is a correction factor that cancels the cascading multiplicative effect of repeated differentiation.
Geometric Interpretation by Degree
| Degree | Captures | Geometry |
|---|---|---|
| Value at | Constant — flat horizontal line | |
| Value + slope | Tangent line at | |
| Value + slope + curvature | Tangent parabola | |
| Higher-order shape | Increasingly accurate near |
A degree-1 Taylor polynomial says “approximate the function with its tangent line.” A degree-2 says “approximate it with the parabola that matches value, slope, and curvature.” Higher degrees match progressively more derivatives.
The Approximation Is Local
Taylor polynomials are accurate near the centre and degrade as grows. A degree-2 approximation of around matches well in but is hopeless at .
You can tighten the approximation by either:
- Increasing the degree — more derivatives matched, more terms.
- Re-centring at a closer point — pick near the of interest.
Many iterative algorithms (including Newton-Raphson) lean on the second strategy: they re-build a low-degree Taylor approximation around the current iterate and step toward its optimum.
Convergence and the Radius of Convergence
The Taylor polynomial uses finitely many terms. The Taylor series takes the limit . Whether that infinite sum equals the original function depends on the function and the chosen centre:
- Convergence: as you add terms, the partial sums get arbitrarily close to a finite value. For centred at , the series converges to for every real , no matter how far from . Smooth functions whose higher derivatives stay tame behave this way.
- Divergence: adding terms fails to approach anything. Partial sums oscillate or blow up.
- Radius of convergence: many functions sit in between. The series converges for inputs within a fixed distance of the centre and diverges beyond it. is the radius of convergence.
A canonical mid-case is centred at . Its Taylor series converges only on — a radius of . At the function blows up to , and the series cannot reach across that singularity even though derivative information at is perfectly well-defined. Beyond the series diverges in the symmetric direction.
ASIDE — A map of a single street corner
Think of the derivative information at as an extremely detailed map of a single street corner — the slope, the curvature, the rate of change of curvature, every higher-order twist. A Taylor polynomial uses that map to mimic the function’s behaviour right around . If the function is smooth enough (like ), the local map accurately guides you across the entire real line. But if there is complicated behaviour nearby (like the singularity of at ), the map only helps for a finite distance — beyond that, the approximation fails and the series spins out of control.
For optimisation purposes, convergence properties matter much less than for analysis. Algorithms like Newton-Raphson take a single step from the current iterate’s quadratic approximation and then re-centre — they never push the approximation out toward its radius of convergence, so divergence never has a chance to bite.
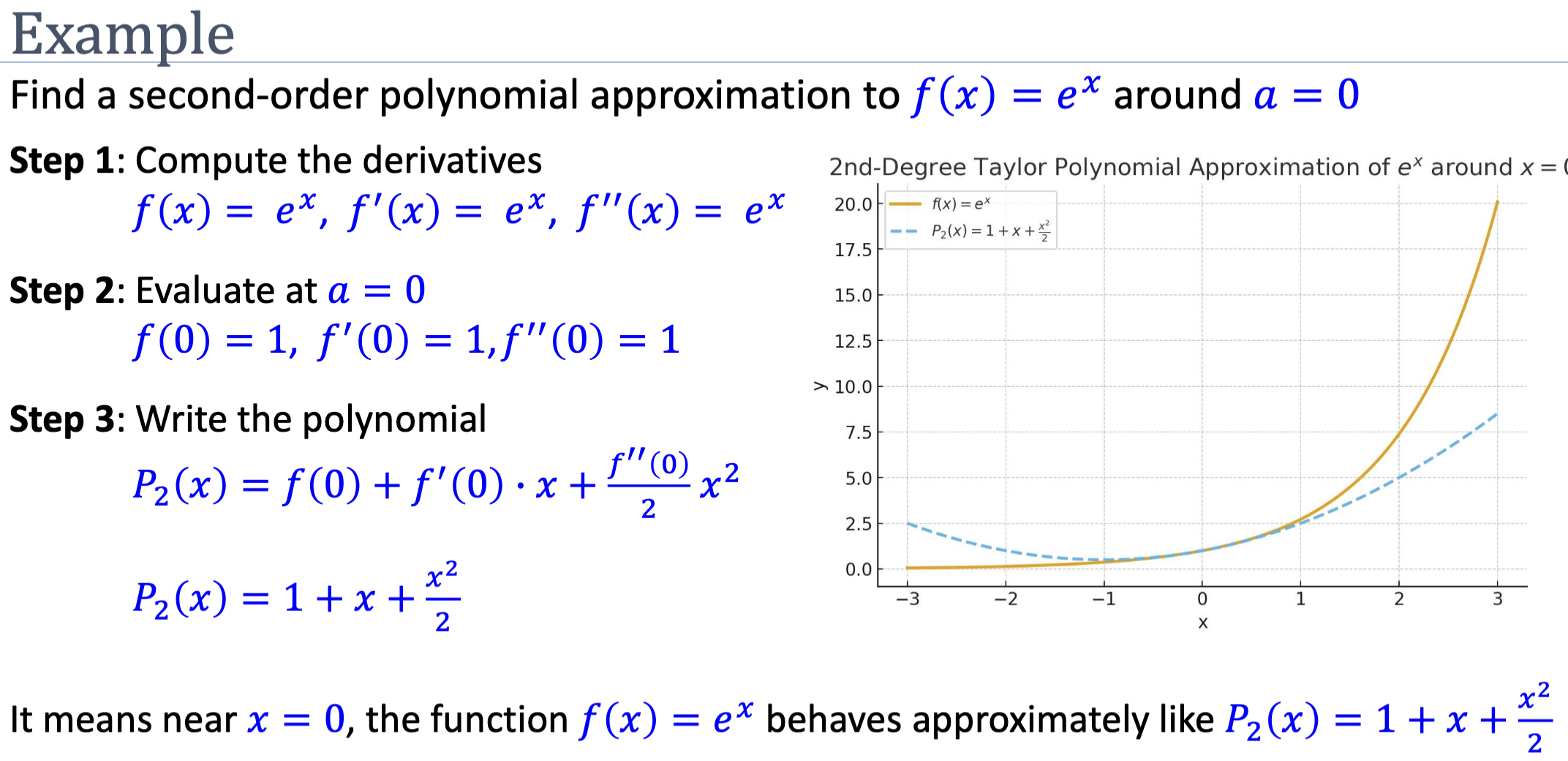
Worked Example: Around
For , all derivatives are , so for every . The degree- Taylor polynomial is:
The degree-2 approximation is very close to for , fair for , poor beyond.


Use in Optimisation
The degree-2 Taylor polynomial of a loss around the current iterate is:
This is a parabola — and a parabola has a closed-form minimum. Setting gives:
This is the Newton-Raphson update. The algorithm replaces the true loss with its quadratic Taylor approximation, jumps to the parabola’s minimum, then re-approximates around the new point. The multivariate generalisation involves the Hessian.
gradient descent can also be derived from a Taylor view: it corresponds to using a degree-1 Taylor approximation plus a fixed step constraint. Because a linear approximation has no minimum (it’s a line), the algorithm needs an externally-supplied step size — the learning rate.
Related
- newton-raphson-method — uses a degree-2 Taylor approximation
- hessian-matrix — the multivariate analogue of
- gradient descent — corresponds (loosely) to a degree-1 Taylor view
Active Recall
Find the second-order Taylor polynomial of around .
, , . At : . So . Near , behaves approximately like this parabola.
Why does the degree-2 Taylor polynomial of a loss function lead naturally to an optimisation update rule, while the degree-1 polynomial does not?
A degree-2 polynomial is a parabola — it has a unique minimum (when curvature is positive) at a closed-form location, derivable by setting its derivative to zero. The optimiser jumps directly there. A degree-1 polynomial is a line, which has no minimum. So the algorithm using a degree-1 view needs an external step size — the learning rate of gradient descent — because it can’t determine “how far to go” from the approximation alone.
Why are Taylor approximations only accurate locally?
The polynomial matches ‘s value and derivatives at the centre , so the two functions agree exactly there. As you move away, higher derivatives that the polynomial doesn’t match start to dominate the difference. Functions whose higher derivatives grow rapidly (like , , near ) lose accuracy quickly; functions whose derivatives stay bounded ( near 0, polynomials) approximate well over wider intervals.
Why is the coefficient of in a Taylor polynomial rather than simply ?
Differentiating four times produces a cascade: , then , then , then . So the fourth derivative of at is , not . Setting that equal to requires . The factorial cancels the multiplicative effect that the power rule manufactures during repeated differentiation.
Why does each Taylor coefficient control exactly one derivative of the polynomial at the centre, independently of the others?
When you take derivatives of and evaluate at , every term of degree higher than still contains an factor and vanishes; every term of degree below has been differentiated to zero already; only the degree- term contributes. So depends on alone. This is what lets us build the polynomial derivative-by-derivative — fixing to match doesn’t disturb any earlier or later coefficient.
The Taylor series for centred at has radius of convergence . Why doesn't it extend further?
has a singularity at , where it diverges to . The radius of convergence cannot reach across a singularity — the derivative information collected at “doesn’t propagate” beyond it. So the series converges on — distance in either direction from the centre — and diverges outside. Functions like have no singularities anywhere on , so their Taylor series converge for every real input.