A first-order iterative optimisation algorithm: from any starting point, repeatedly step in the direction of the negative gradient, scaled by a learning rate. The workhorse of machine learning optimisation.
The Algorithm
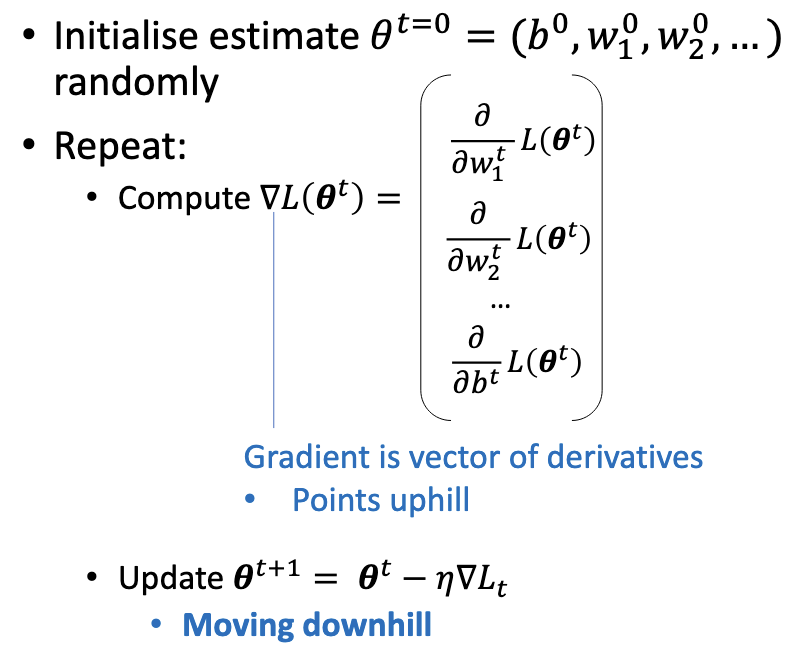
To minimise a differentiable function :
- Initialise (often zeros or small random values).
- Repeat until convergence:
The hyperparameter is the learning rate. Convergence is typically declared when falls below a threshold or after a fixed number of iterations.
Why It Works
The gradient is the vector of partial derivatives, pointing in the direction of steepest increase of . The negative gradient points in the direction of steepest decrease. By the definition of the derivative, for a small enough step in that direction, is guaranteed to decrease.

The qualifier “small enough” is critical. The negative gradient is the steepest direction instantaneously; over a finite step it may overshoot the minimum or move into a region where the gradient itself has changed substantially.
The Learning Rate Trade-off
Picking is a balancing act:
- Too large: each step jumps past the minimum, possibly landing on the opposite slope at higher loss. Iterations bounce around or diverge.
- Too small: each step moves a negligible distance. Convergence still happens but takes prohibitively many iterations.
There is no universally right — it depends on the curvature of . Practically, one tries a few values (e.g., ), watches the loss curve, and adjusts. More sophisticated schemes (decay schedules, line search, adaptive methods like Adam) handle this dynamically.
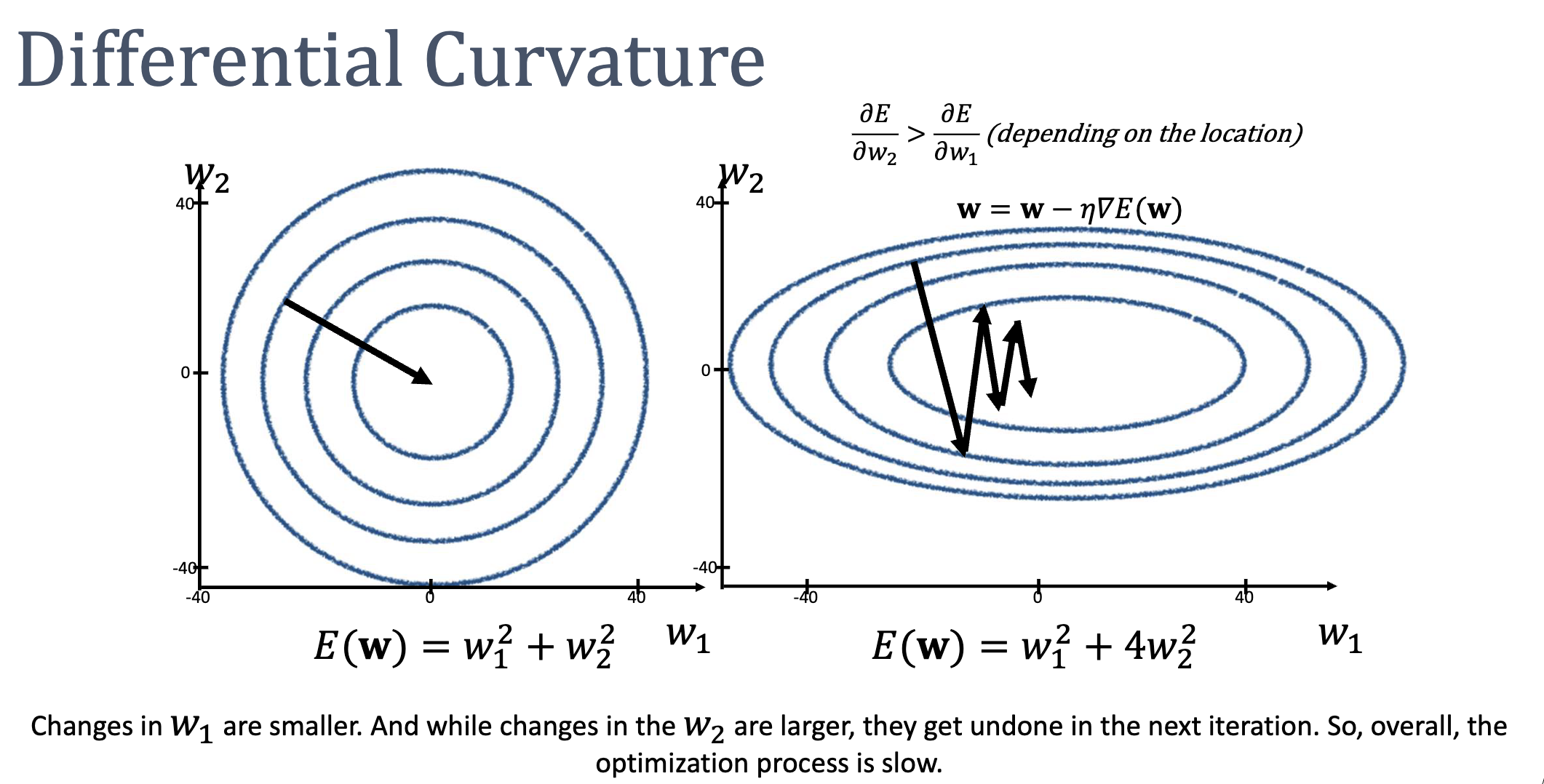
Differential Curvature: The Achilles Heel
The same scales every dimension of the update. This breaks down badly when different weights have different curvature — i.e., the loss surface is shaped like a long narrow valley rather than a round bowl.
Consider . The contours are ellipses, with four times steeper than . Gradient descent’s path zigzags across the narrow direction while creeping slowly along the long direction:
- Set small enough to avoid overshooting in → updates become tiny.
- Set large enough to make progress in → overshoots and bounces.
The fundamental problem: gradient descent uses only first-order (slope) information. It has no idea how the slope itself is changing across the surface.
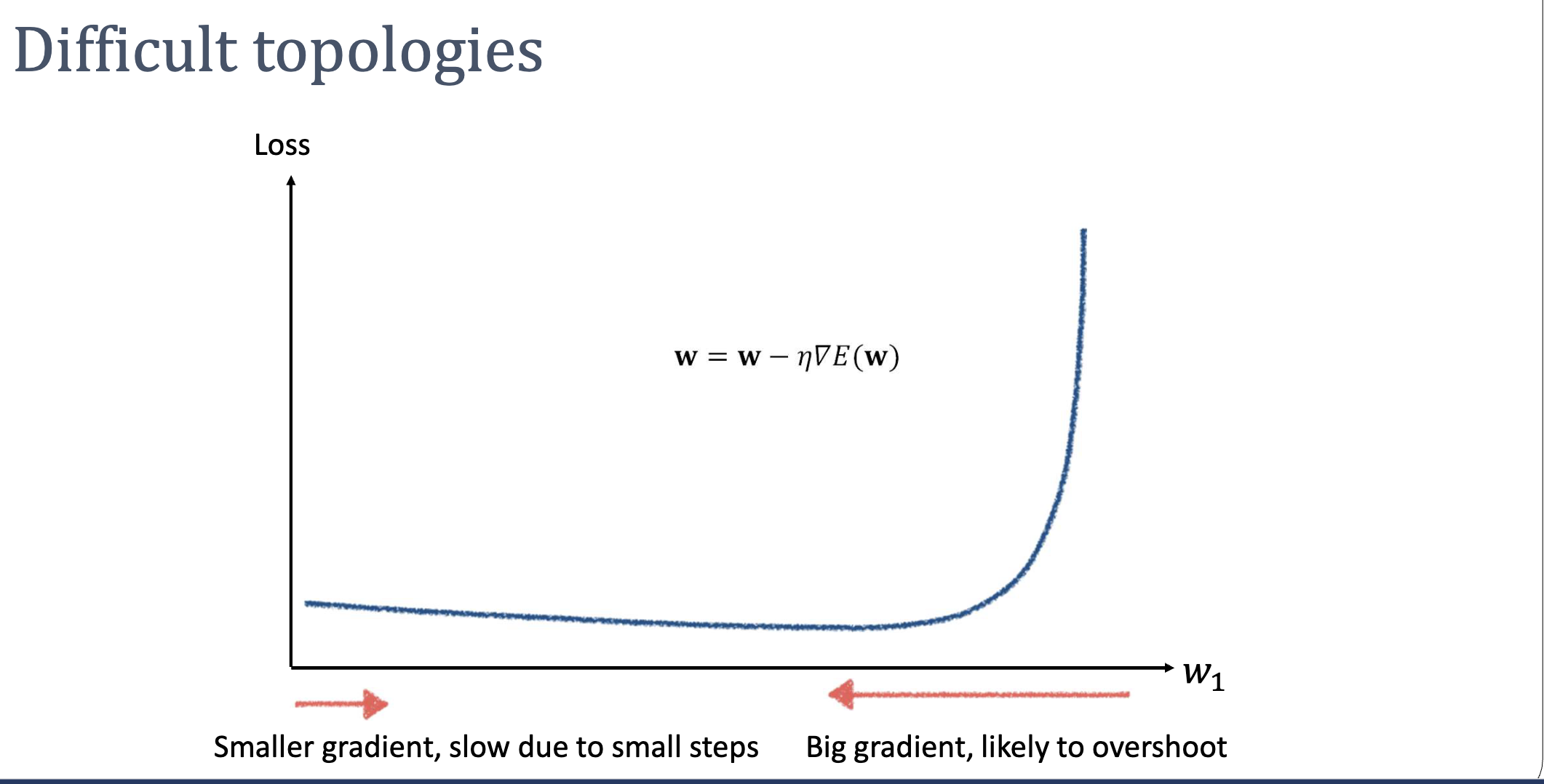
The same pathology shows up in 1D when the loss is shallow on one side and explodes on the other — a single can’t be both large enough for the flat region and small enough for the steep one:
ASIDE — Standardisation helps but isn't a cure
Standardising input features (zero mean, unit variance) often reshapes the loss surface from ellipses toward circles, mitigating curvature mismatch. But the loss landscape’s geometry is shaped by feature interactions and the loss function’s structure, not just feature scales — so standardisation alleviates the issue without eliminating it. To actually adapt to local curvature, you need a second-order method like Newton-Raphson.
Local Minima
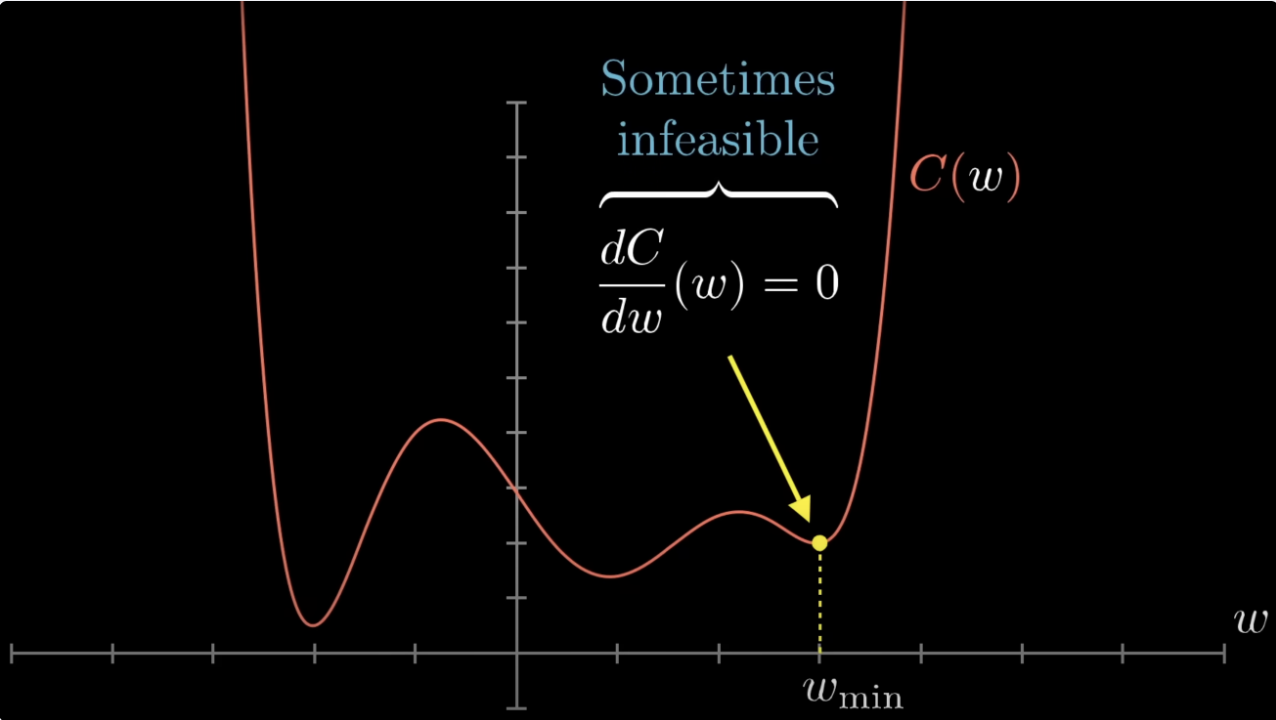
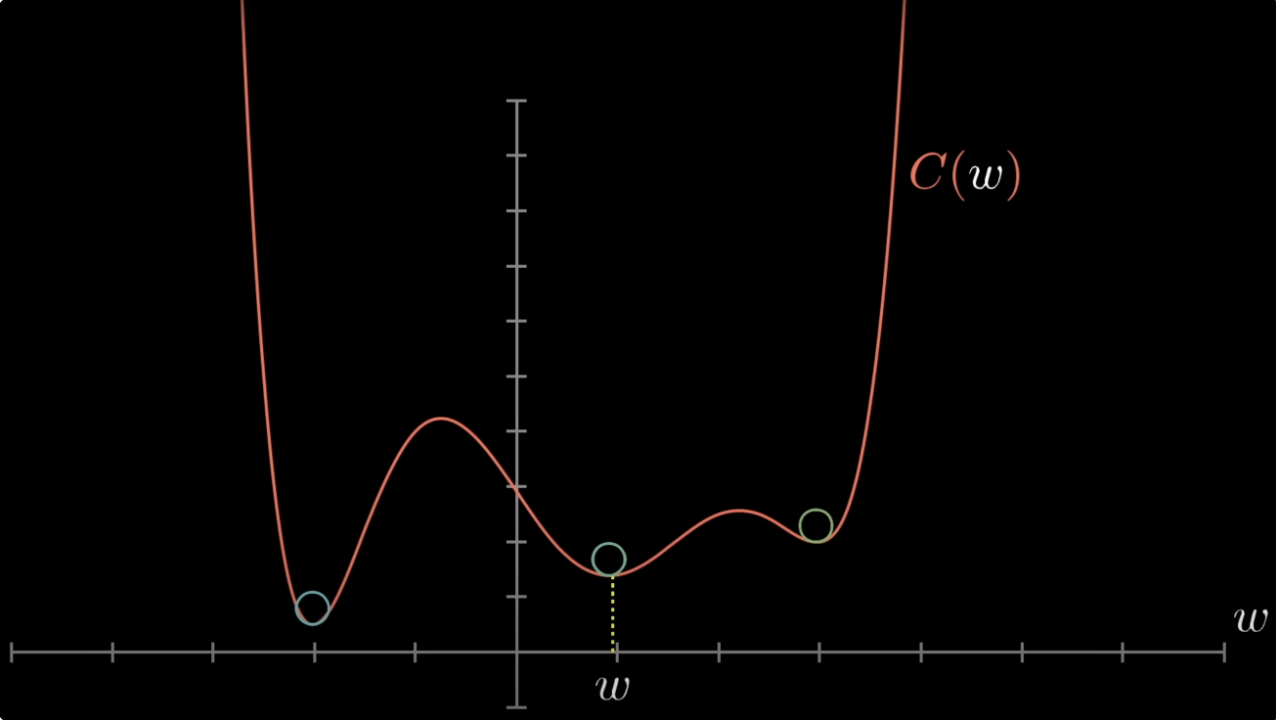

Gradient descent finds a critical point (where ), not necessarily the global minimum. On non-convex losses (e.g., neural networks), it can get stuck in local minima or saddle points.
For convex losses, this isn’t a worry: every local minimum is a global minimum. The cross-entropy-loss for logistic-regression is strictly convex in , so gradient descent that converges to a critical point converges to the unique global optimum.
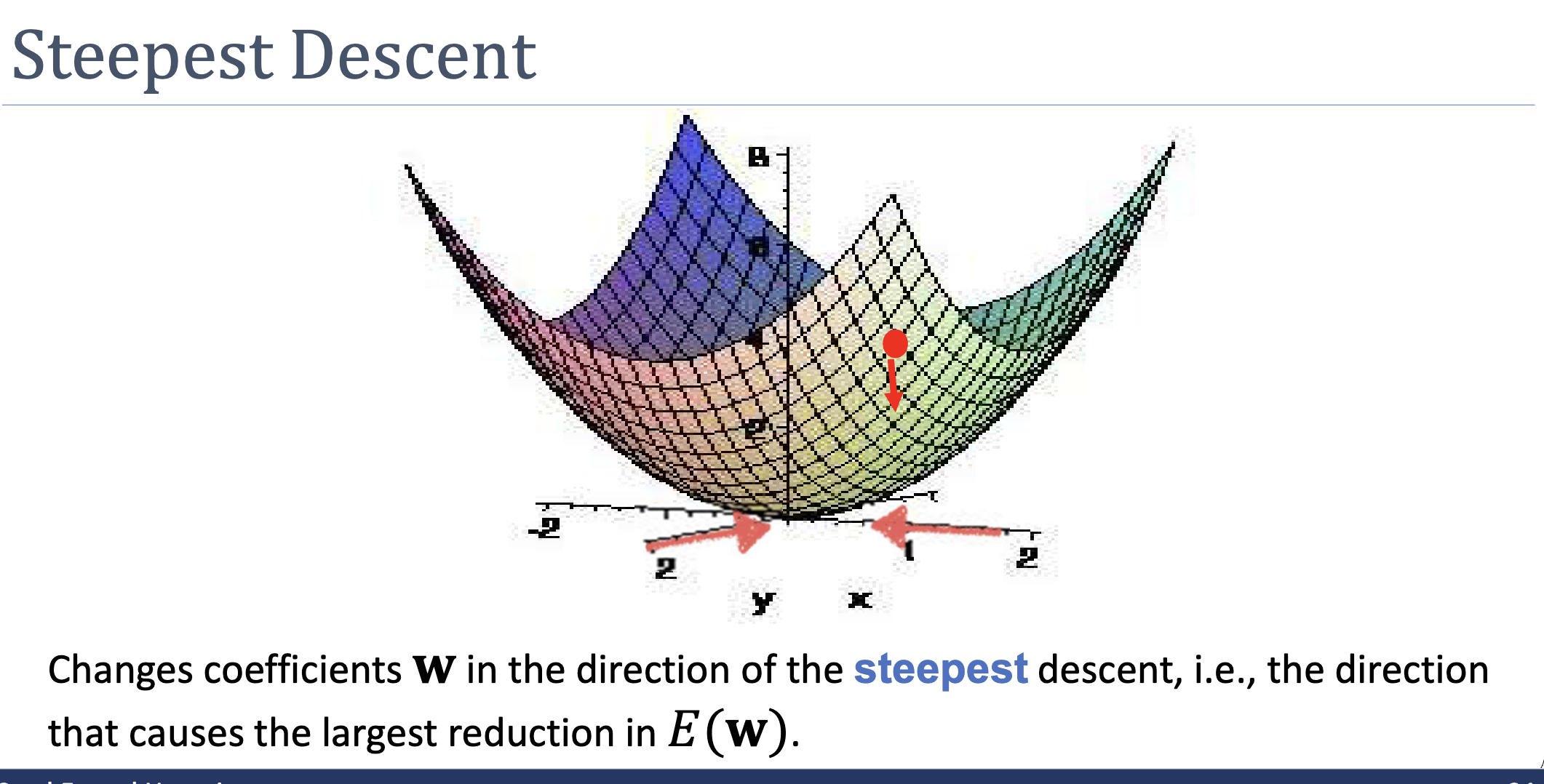
Steepest Descent Is Only Locally Optimal
The negative gradient is the direction of steepest descent at the current point. It is not guaranteed to be the best direction over a longer trajectory. In a long narrow valley, the best direction is along the valley toward the minimum, but the steepest direction at most points is roughly perpendicular to the valley (pointing toward the closer wall). This mismatch is why gradient descent zigzags.
The Update Rule for Logistic Regression
For logistic-regression with cross-entropy-loss:
so the gradient descent update is:
Each step requires summing over the entire training set — this is batch gradient descent. Variants include stochastic (one example per step) and mini-batch (a subset per step), trading update accuracy for speed.
Related
- cross-entropy-loss — the loss gradient descent typically minimises for logistic regression
- newton-raphson-method — second-order alternative that adapts step size to curvature
- convex-function — the property that lets gradient descent succeed reliably
- taylor-polynomial — gradient descent corresponds to using a degree-1 Taylor approximation
Active Recall
Suppose the loss surface has very different curvatures along different axes. What pathological behaviour will gradient descent exhibit, and why does standardising input features only partially fix it?
Gradient descent zigzags: large gradient components along the high-curvature axes cause overshooting and bouncing, while small components along the low-curvature axes produce glacially slow progress along the valley toward the minimum. Standardising features rescales them to similar magnitudes, which often makes the loss surface more isotropic — but the curvature of the loss is determined by feature interactions and the loss function’s structure, not just feature scales. To genuinely adapt to local curvature, you need second-order information (the Hessian).
Why is gradient descent guaranteed to find the global minimum of the cross-entropy loss for logistic regression but not, in general, for a neural network?
The cross-entropy loss for logistic regression is strictly convex in , so it has a unique global minimum and any critical point is that minimum. A neural network’s loss is non-convex in its parameters (because the network is a non-convex function of its weights), so gradient descent can converge to local minima or saddle points that are not the global optimum.
Walk through one gradient descent iteration on with starting point and . What does this illustrate about choosing poorly?
, so . Update: . The next gradient is , so . The iterations oscillate around the optimum at rather than converging monotonically. This is the symptom of a learning rate that is large relative to the curvature: progress happens, but with overshoot. (At we would oscillate forever; at we would diverge.)