Break the network on purpose during training. Each step, randomly turn off a fraction of neurons — they output zero, contribute nothing to the forward pass, and receive no gradient. The network can never lean on any specific neuron always being there, so it learns to spread its representation across many redundant pathways. The effect is strong regularisation at almost no cost.
The idea
At each training step, for each neuron in a layer where dropout is applied, flip an independent biased coin: with probability (the dropout rate, typically –) the neuron is dropped — its output is set to zero for this step. The remaining neurons fire as usual.
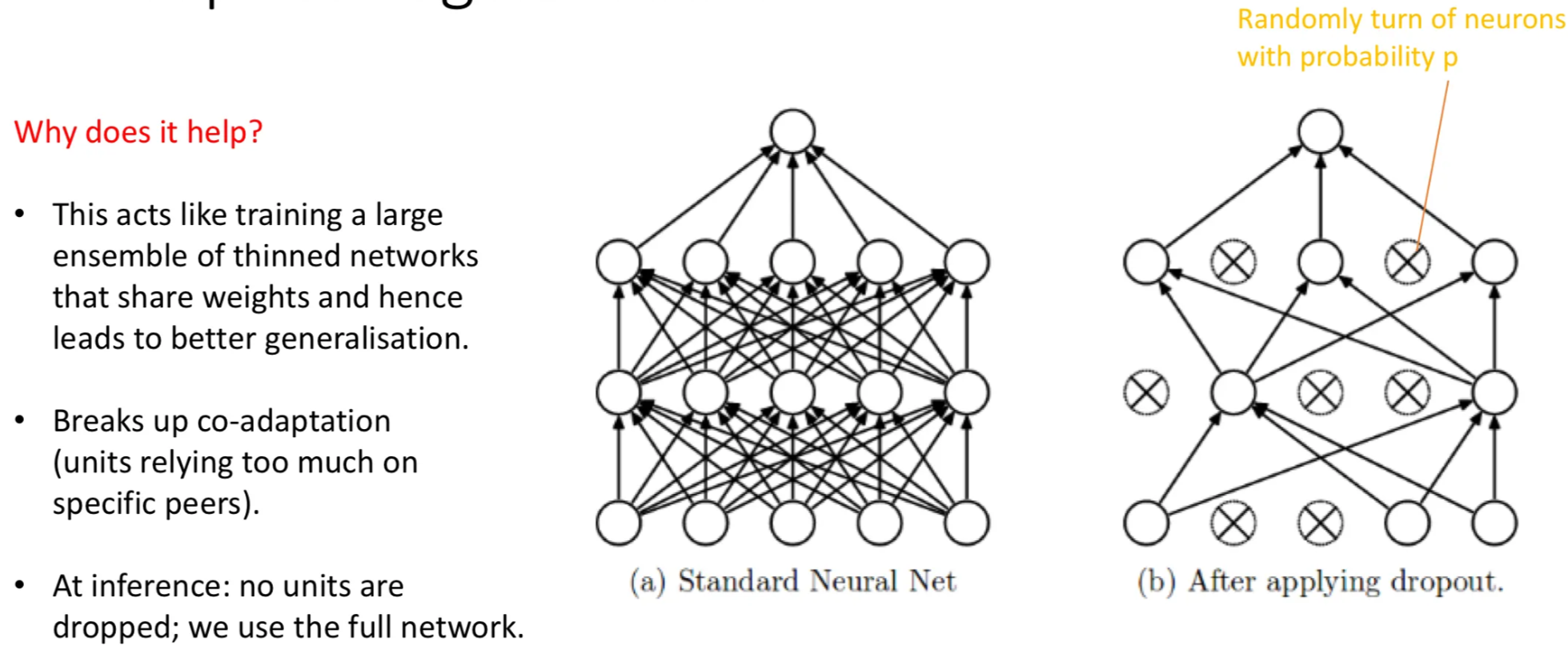
The left network is the standard fully-connected MLP; the right shows what one training step looks like with dropout applied: the crossed-out neurons are gone for that step. Different neurons get dropped at the next step, then again at the next. Every iteration trains a different “thinned” sub-network.
Why does this help?
Two complementary stories explain why deliberately breaking the network during training improves generalisation.
Story 1: ensemble of thinned networks. Each training step, a different random sub-network is active. With neurons available for dropout, you have possible sub-networks (each independently on or off), all sharing the same underlying weights. Training is effectively training a huge ensemble of these thinned networks simultaneously — and ensembles famously generalise better than any single model. At inference, using the full network averages over them implicitly.
Story 2: breaking co-adaptation. Without dropout, neurons can become co-adapted: neuron 47 only works because neuron 23 is always firing in tandem to compensate for its mistakes. The pair memorise something specific to the training set. Drop neuron 23 randomly and the pair-trick fails — neuron 47 has to be useful on its own, with whatever neighbours happen to be active. Each neuron is forced to learn features that are robust to the absence of any particular peer. The result is a more distributed, more robust internal representation.
TIP — Dropout is "rough love" regularisation
The intuitive analogy: a student who studies in groups becomes useless on their own; a student who’s forced to study alone half the time learns to be self-sufficient and does better when reunited with the group. Dropout deliberately denies the network the comfort of relying on its peers, and the resulting independence is what generalises.
Train time vs inference
Dropout is a training-time technique only. At inference, all neurons are kept — you use the full network’s predictions, not a randomly-thinned subset.
But this raises a numerical issue. At training time, only a fraction of neurons in a dropout layer fire on any given step, so the expected total activation reaching the next layer is multiplied by . At inference, all neurons fire, so the activation magnitudes are larger by a factor of relative to what downstream layers were trained on.
Two equivalent fixes:
- Inverted dropout (modern default): at training time, scale the surviving activations up by . So at inference no rescaling is needed — the full-network activations already match the training-time expected magnitudes.
- Original formulation: at inference time, scale all activations down by .
Both achieve the same thing. PyTorch’s nn.Dropout uses inverted dropout under the hood; you toggle it via model.train() (active) and model.eval() (passive).
Where to put dropout
Dropout is typically applied:
- After fully-connected layers in the FC head of a CNN or in MLPs. This is its original use case, and where it’s most effective. Dropout rates of are common for the wide FC layers of classical CNNs.
- Less often, after conv layers. Convolutional layers already have weight sharing as a form of regularisation, so dropout is more redundant there. When it is used, the rate is typically lower (–). A variant called spatial dropout drops entire feature maps rather than individual pixels, since neighbouring pixels in a feature map are highly correlated and dropping them independently is less effective.
- Not on output layers. You want a clean prediction at the final layer.
Empirical effect
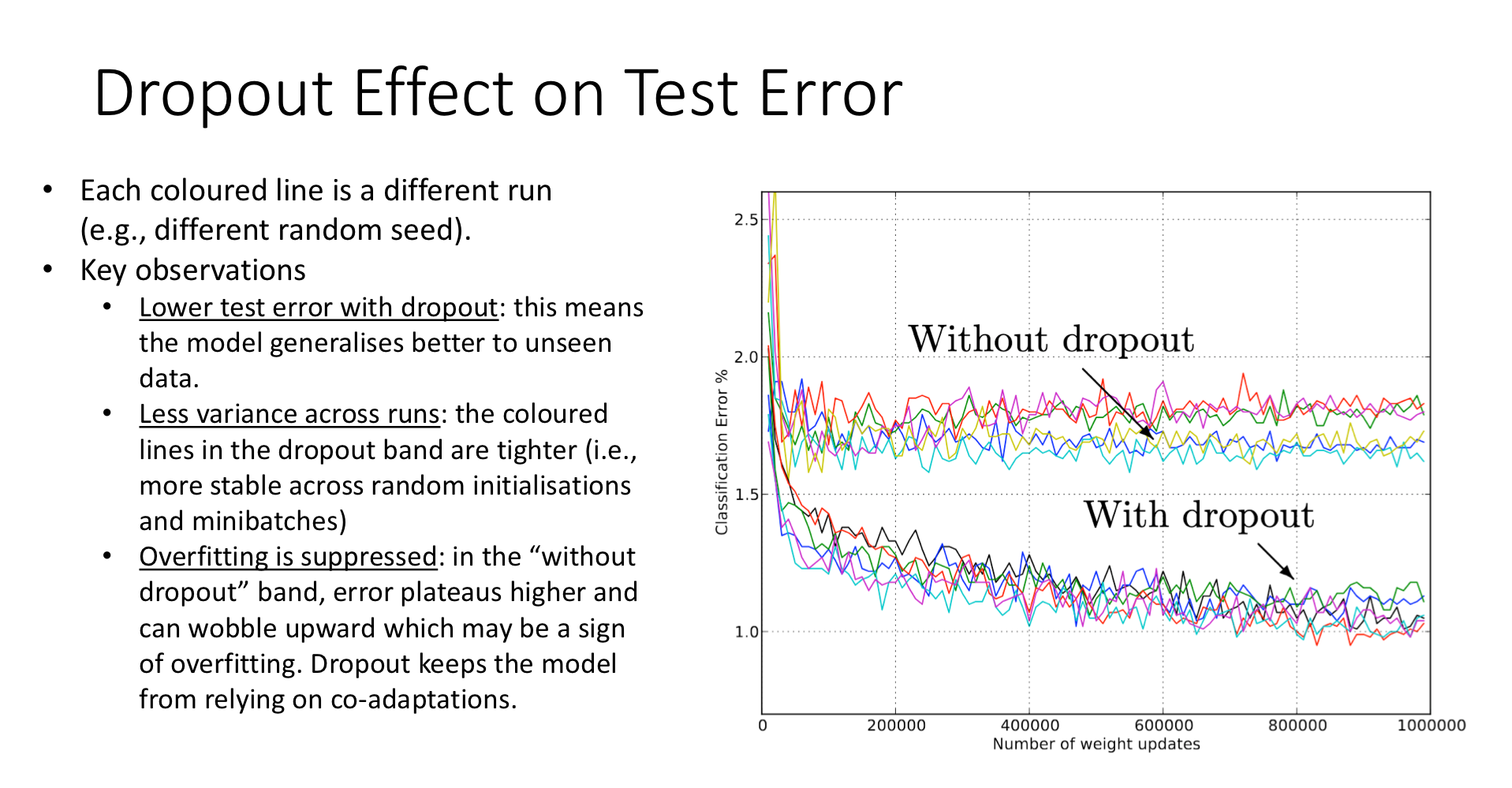
This plot shows the test error of an image classifier across many training runs (each coloured line is one run). The upper band is without dropout; the lower band is with dropout. Three observations:
- Lower test error. The model with dropout generalises better — the entire band sits below the no-dropout band, by ~1 percentage point.
- Less variance across runs. The dropout band is tighter, indicating the technique is more robust to the random seed.
- Overfitting suppressed. The no-dropout band plateaus and starts wobbling upward (a sign of slow overfitting); the dropout band keeps decreasing. Training longer is safer with dropout.
Dropout in modern architectures
Dropout was the dominant regulariser for CNN-era image classifiers. In modern architectures, its role has shrunk:
- CNNs with batch normalisation often don’t need dropout — batch norm has its own implicit regularisation effect, and stacking it with dropout can hurt. Modern CNNs (ResNet, EfficientNet) often use only minimal dropout, or none at all.
- Transformers still use dropout heavily — between attention layers, between FC blocks. It remains essential there.
So dropout is still alive and well, but where you put it depends on what other regularisation the architecture already provides.
Related
- regularization — dropout sits alongside L2 weight decay, early stopping, and data augmentation as a regulariser
- overfitting — the problem dropout solves
- normalization — batch normalisation is a partial substitute in CNNs
- data-augmentation — another regulariser; the two are commonly stacked
Active Recall
Explain the "ensemble" interpretation of dropout. How does randomly disabling neurons during training relate to ensembling?
At each training step, a random subset of neurons is active — call this a thinned network. With droppable neurons, there are possible thinned networks, all sharing the same underlying weights. Each training step is one step of gradient descent on one of these networks (the one whose neurons happen to be active). Over many steps, every thinned network is trained at least a little, and the shared weights are the average of what works for all of them. At inference, the full network is used — implicitly averaging the predictions of all those thinned networks. Ensembles generalise better than single models, which is why dropout helps.
A network has dropout layers with rate . At training time, half the neurons are off; at inference, all are on. If we don't compensate, what goes wrong, and what's the standard fix?
Without compensation, the activations entering downstream layers at inference are roughly twice as large as at training (since all neurons fire instead of half). Downstream layers were trained on smaller-magnitude inputs and produce wrong outputs at inference. Inverted dropout fixes this by scaling surviving activations up by during training; at inference no rescaling is needed, and the magnitudes match what the network was trained on.
Why is dropout switched off at inference time?
Dropout’s purpose is to prevent over-reliance on specific neurons during training. At inference, you want the most accurate prediction possible — using the full network, with all learned features active, is strictly better than using a random thinned subset (which would just inject prediction noise for no benefit). Dropout is a training-only intervention.
Why is dropout less commonly used inside CNN convolution layers compared to fully-connected layers?
Two reasons. First, convolution already has weight sharing as an implicit regulariser — there are far fewer parameters per layer to memorise training data, so the overfitting pressure is lower. Second, neighbouring pixels in a feature map are highly correlated; dropping them independently is less disruptive than dropping independent FC neurons, because the surviving pixels carry essentially the same information. A variant called spatial dropout (drop entire feature maps, not individual pixels) is sometimes used to address this.
A classmate trains a model with both batch normalisation and aggressive dropout ( ) on every layer. The model performs worse than the same model with only batch norm. Why?
Batch norm and dropout don’t always combine cleanly. Batch norm computes statistics from the current batch’s pre-activations; if dropout has already zeroed out half of those, the statistics are noisier and the normalisation is less stable. Beyond that, batch norm provides its own regularisation effect (each example sees noisy statistics from its mini-batch peers), so the additional regularisation from dropout can over-constrain the model and hurt fitting capacity. The modern advice for CNNs is to use mostly batch norm, with low or no dropout; for transformers, the opposite (dropout heavy, layer norm only).