THE CRUX: We left week 3 with an SVM that works — but it sits in a -space that's potentially huge (or infinite-dimensional). How do we actually solve it without paying that cost? And once we know the answer, how does it change our view of "what kind of similarity matters"?
The fix is to dualise the SVM optimisation. The primal asks for a hyperplane in -space; the dual reformulates this in terms of how training points relate to each other through inner products . Once it’s all about inner products, we can replace them with a kernel function that returns the same value computed entirely in the original space — never forming . That’s the kernel trick. It transforms expressive but expensive embeddings into cheap function calls, opens the door to infinite-dimensional feature spaces (Gaussian kernels), and lets us define similarity directly on objects without numeric features (strings, trees, graphs).
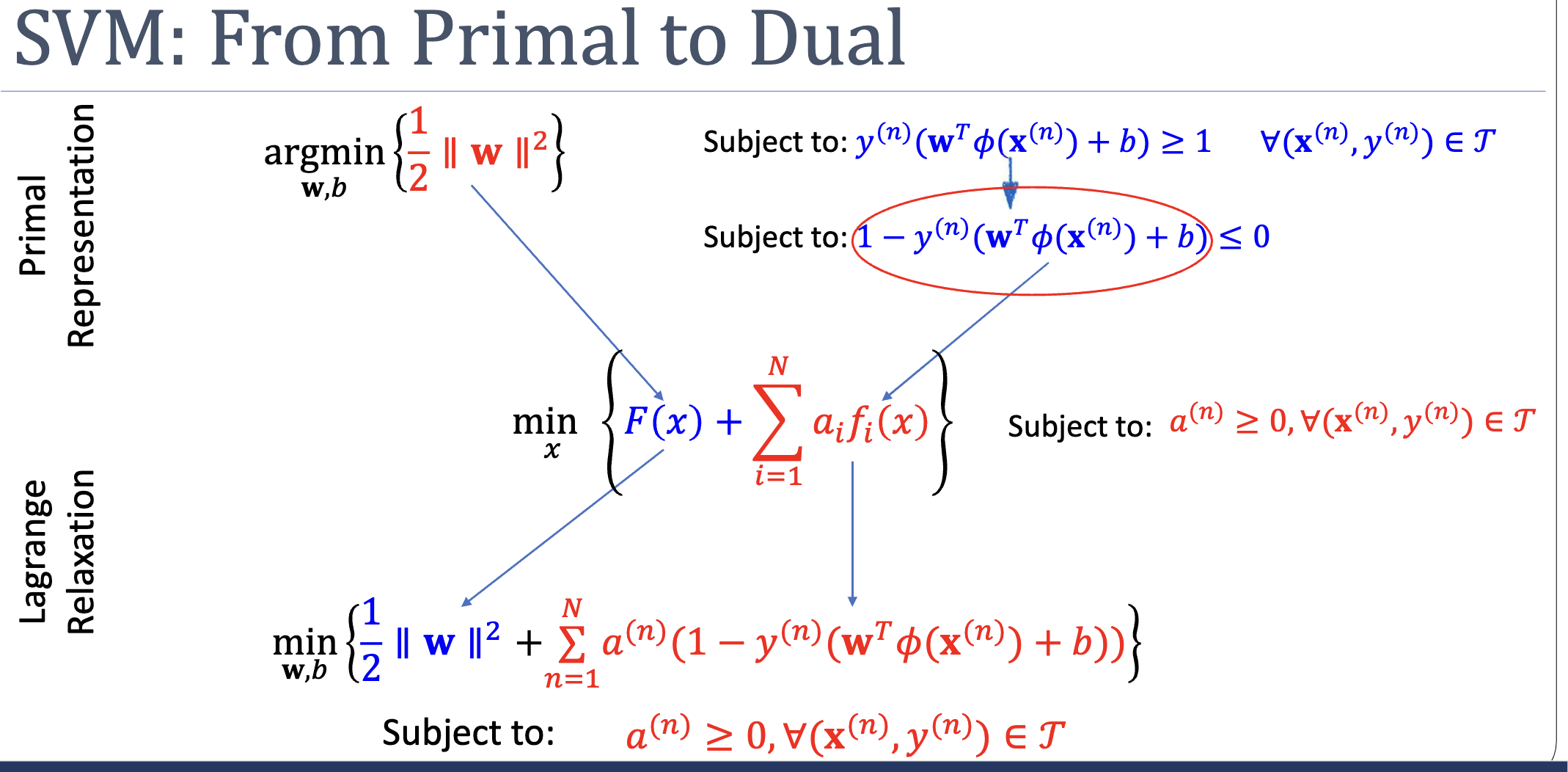
Week 3 set up the SVM primal:
This is a quadratic program — convex, with a unique global optimum, solvable by off-the-shelf QP solvers. Job done, in principle. But two problems hide behind the formulation:
- The embedding may be enormous. With 100 inputs and a degree-3 polynomial expansion, has tens of thousands of components. The QP has thousands of variables. With a Gaussian-style kernel, is infinite-dimensional and we can’t compute it at all.
- The optimisation operates on the wrong currency. The primal works with the parameters . To say anything about a new test point we still need — same cost.
This week’s payoff: a different formulation of the same problem that depends on data only through inner products . Once we have that, we can replace each inner product with a kernel function evaluated in the original space, and never touch again.
Part 1: Lagrange Relaxation
The standard tool for handling inequality constraints is the Lagrangian. Instead of forbidding regions where , we fold the constraint into the objective via a non-negative multiplier :
When a constraint is violated (), the term inflates — the optimiser is pushed away from infeasible . When satisfied (), the term is non-positive and at the optimum it’s zero (the multiplier “switches off”).
But naive Lagrangian relaxation has a problem: with fixed , the penalty might be too small to enforce the constraint. The fix is to maximise over :
If a constraint is violated, the inner max sends , making infinite — the outer min refuses to land there. If all constraints are satisfied, the inner max settles at (or wherever ), giving . The minimax exactly reproduces the original constrained primal.
The Dual: Swapping Min and Max
The minimax requires solving a constrained max inside an unconstrained min — still awkward. The dual swaps the order:
Now the inner min is unconstrained. We can attack it with , which often produces a closed form for in terms of . Substituting back gives a problem purely in .
Two duality theorems govern when this is safe:
- Weak duality (always): . The dual gives a lower bound on the primal.
- Strong duality (when convex + Slater’s condition holds — both true for SVM): the inequality is equality. Dual and primal have the same optimum.
When strong duality holds, the optimum is a saddle point of : a min along the direction, a max along the direction. Walking down-then-up or up-then-down both arrive at the same point.
KKT: When Are We Optimal?
Stationarity () is necessary and sufficient for unconstrained convex optimisation. With inequalities, we need more. The KKT conditions state that a primal-dual pair is jointly optimal iff:
- Stationarity. .
- Complementary slackness. for all — either the multiplier is zero or the constraint is active.
- Primal feasibility. .
- Dual feasibility. .
Complementary slackness is the structural reason SVMs are sparse — and we’ll see why shortly.
Part 2: SVM in Dual Form
Apply this machinery to the SVM primal. First, rewrite the constraint as . The Lagrangian:
The minimax is:
Take the inner min by setting partials to zero:
Substituting back into and using the second relation, and both vanish from the optimisation, leaving:
subject to and .
This is the SVM dual problem. Three things to notice:
- The unknowns are now , not . The dual has variables (one per training example), independent of . When , the dual is much smaller.
- The data appears only through inner products . This is the opening for the kernel trick.
- The objective is concave in — still a QP, still solvable.
Sparsity from Complementary Slackness
KKT’s complementary slackness says, for each training point:
Either:
- : the point sits strictly outside the margin envelope. It contributes nothing to the dual sum — and nothing to .
- : the point is on the margin — a support vector. These have .
So at the optimum, only support vectors have non-zero multipliers. Predictions only need the support vectors — every other training point can be deleted. Sparsity is structural, not heuristic.
Predictions in the Dual
Substituting into :
where is the set of support-vector indices. For , use the fact that any support vector satisfies , solve for , and average over all support vectors for numerical stability:
Predict by checking the sign of .
Notice: everything depends on only through pairwise inner products.
Part 3: The Kernel Trick

Define a kernel function . Replace every inner product in the dual with :
Now is implicit. The algorithm needs only , which we can often evaluate in — independent of .
The Worked Example
Let — a 6-dimensional polynomial-of-degree-2 embedding for 2D inputs. Computing the inner product:
Six multiplications in feature space collapse into one inner product plus one square in the original space. Generalising:
is the [[polynomial-kernel|polynomial kernel of degree ]] — corresponds to the embedding of all monomials of degree . A 100-dimensional input with implies feature dimensions, but the kernel computes in 100 multiplications.
Mercer’s Condition: Which Functions Are Valid Kernels?
We’ve been assuming there’s a such that . Not every “similarity-shaped” function admits such a . The criterion is Mercer’s condition:
For any finite set of points, the Gram matrix must be:
- Symmetric: .
- Positive semidefinite: for all .
If both hold, corresponds to an inner product in some Hilbert space — Mercer’s theorem guarantees the existence of without requiring us to compute it. Algorithmically, positive semidefiniteness keeps the SVM dual a convex QP; without it, the optimisation can wander to nonsense.
Building Kernels Without Verifying Mercer
Verifying Mercer’s condition from scratch is hard. Instead, build kernels by composition. Given valid , the following are also valid:
The polynomial kernel is built this way: start from (valid), apply , done.
The Gaussian (RBF) Kernel
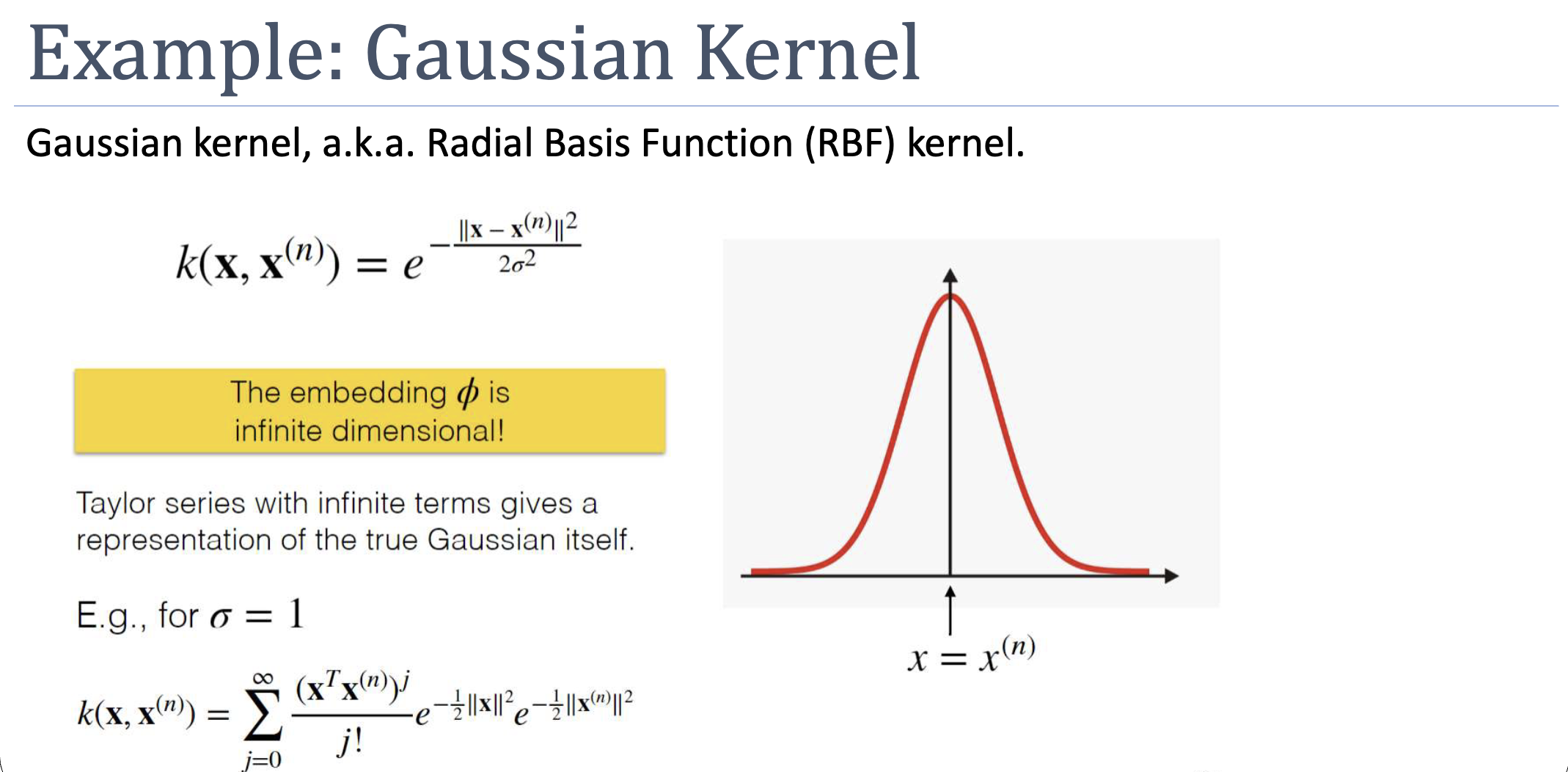
The implicit is infinite-dimensional — its Taylor series contains monomials of all degrees. We could never compute explicitly, but the kernel-trick sidesteps that: is one subtraction, one squared norm, one exponential.
The validity proof chains the composition rules from :
- valid (polynomial of with non-negative coefficients).
- valid (sum of valid kernels, or directly the exponential rule).
- with → exactly the Gaussian kernel.
The Gaussian is the default non-linear kernel: maximally expressive, no strong structural assumptions. It pairs naturally with SVM’s margin-maximisation — even with infinite-dimensional features, maximising margin keeps the boundary regularised.
ASIDE — Kernels for non-numeric data
Once we accept that doesn’t have to be constructed explicitly, kernels can be defined directly on objects without numeric features. The all-subsequence kernel for strings counts how many subsequences are shared (computable in via dynamic programming). The all-subtree kernel for parse trees counts shared subtrees. The set kernel counts shared subsets. Each of these implies an embedding into a high-dimensional space — but we never realise it, just evaluate the kernel.
Part 4: When to Pick Which Kernel
| Kernel | When | Caveat |
|---|---|---|
| Linear | High-dim input, linearly separable | Can’t capture non-linearity |
| Polynomial | Polynomial structure suspected (vision) | Sensitive to ; high-degree overfits |
| Gaussian / RBF | Default for non-linear; no strong prior | Needs careful ; sensitive to feature scale |
| Custom (string, tree, graph) | Domain-specific structure | Must verify Mercer or compose validly |
The sklearn SVC default is RBF for good reason — it’s the kernel that asks the fewest assumptions of the data.
What Could Go Wrong
- Overfitting. Gaussian kernel maps to infinite-dimensional space; without margin maximisation it would memorise the training data. Hard-margin SVM with the wrong still overfits. Soft-margin SVM (next week) introduces slack to mitigate this.
- Non-Mercer kernels. A function that “looks like similarity” but fails positive semidefiniteness yields a non-convex dual, with no guarantee of finding the optimum and no margin interpretation. Stick to validated building blocks.
- Feature scaling. Both polynomial and Gaussian kernels depend on or — the largest-scale feature will dominate. Standardise inputs first.
Concepts Introduced This Week
- lagrangian — the Lagrangian function and Lagrange duality; how minimax/maxmin let us swap a constrained primal for an unconstrained-inner dual.
- kkt-conditions — Karush–Kuhn–Tucker optimality conditions for convex constrained optimisation; complementary slackness is what produces SVM’s sparsity.
- kernel-trick — replace inner products with a kernel function computed in the original space.
- mercers-condition — symmetric + positive-semidefinite Gram matrix tests whether a candidate function is a valid kernel.
- gaussian-kernel — Radial Basis Function kernel; infinite-dimensional embedding; default choice for non-linear SVM.
- polynomial-kernel — finite-dimensional embedding of all monomials up to degree .
Connections
- Builds on week-03: takes the SVM primal (a QP in -space) and dualises it; the support-vector intuition becomes a structural KKT consequence rather than a mere observation.
- Builds on non-linear-transformation: kernels generalise basis expansion — same boundary shape, no need to ever materialise .
- Sets up later weeks: soft-margin SVM (relaxes the hard-margin constraint to handle non-separable data); regularisation and bias-variance (overfitting risk for high-capacity kernels); generalisation theory (why margin maximisation regularises infinite-dimensional embeddings).
Open Questions
- What if the data isn’t separable even in the kernel-induced space? (Soft-margin SVMs with slack variables — next week.)
- How do we choose the kernel and its hyperparameters in practice? (Cross-validation; later weeks formalise this as model selection.)
- Why does maximising margin still give a well-behaved boundary even when the implicit is infinite-dimensional? (VC dimension / generalisation bounds, in weeks 8–10.)