A trick for handling inequality constraints: instead of enforcing from outside the optimisation, fold a penalty into the objective, with a Lagrange multiplier. The resulting Lagrangian can be optimised by alternating min over and max over — and under the right conditions, swapping the order (“strong duality”) gives an equivalent but often easier problem.
The Setup: Constrained Convex Optimisation
We have a primal problem:
We’d like to use unconstrained calculus (), but the constraints get in the way. They forbid certain regions of -space, and the unconstrained minimum may sit in a forbidden region.
Lagrange Relaxation
Form the Lagrangian:
The are Lagrange multipliers. They re-express the constraints as a penalty:
- If a constraint is violated (), the term is positive — it inflates the objective, pushing the optimiser away from infeasible .
- If a constraint is satisfied (), the term is — at best it helps the objective, at worst it does nothing.
Minimax Primal Formulation
A naive Lagrangian relaxation has a problem: with fixed multipliers, the penalty for violation may be too small. The fix is to maximise over , then minimise over :
Reading the inner max:
- If any constraint is violated (), the inner max can drive , sending . The outer min refuses to land there.
- If all constraints are satisfied, every , so the inner max is achieved at (or wherever ), giving .
So the minimax exactly reproduces the constrained primal — no information is lost.
The Dual Formulation
The minimax requires solving a constrained max problem inside an unconstrained min — still awkward. The dual swaps the order:
Now the inner min is unconstrained (no inequality constraints on alone), so we can attack it with . This often yields a closed-form expression for in terms of , which we substitute back to get a problem in alone.
Weak Duality
Always true:
The dual gives a lower bound on the primal optimum. The gap between them is the duality gap.
Strong Duality
When the gap is zero — primal and dual have the same optimal value — we say strong duality holds. Two sufficient conditions:
- and all are convex ( is convex in for fixed , concave in for fixed ).
- Slater’s condition: there exists at least one strictly feasible with for all .
Both hold for SVM and most ML problems, so we can freely move between primal and dual representations.
TIP — Saddle point picture
When strong duality holds, the optimum is a saddle point of : a minimum along the axis and a maximum along the axis. Whether you walk down then up (minimax) or up then down (maxmin), you arrive at the same point.
Why Bother Going to the Dual?
Three reasons that show up in SVM:
- The inner min has closed form. Setting and solving eliminates , leaving a problem purely in .
- The dual may have fewer variables. SVM primal has unknowns ( where ); SVM dual has unknowns (one per training point). When (high-dimensional embedding, modest training set), the dual is dramatically smaller.
- The dual depends on only through inner products . This opens the door to the kernel-trick — replace inner products with a kernel function and never compute at all.
Worked Example: SVM Primal → Lagrangian → Minimax → Dual
The SVM constraint is rewritten as , which slots straight into the Lagrangian template:
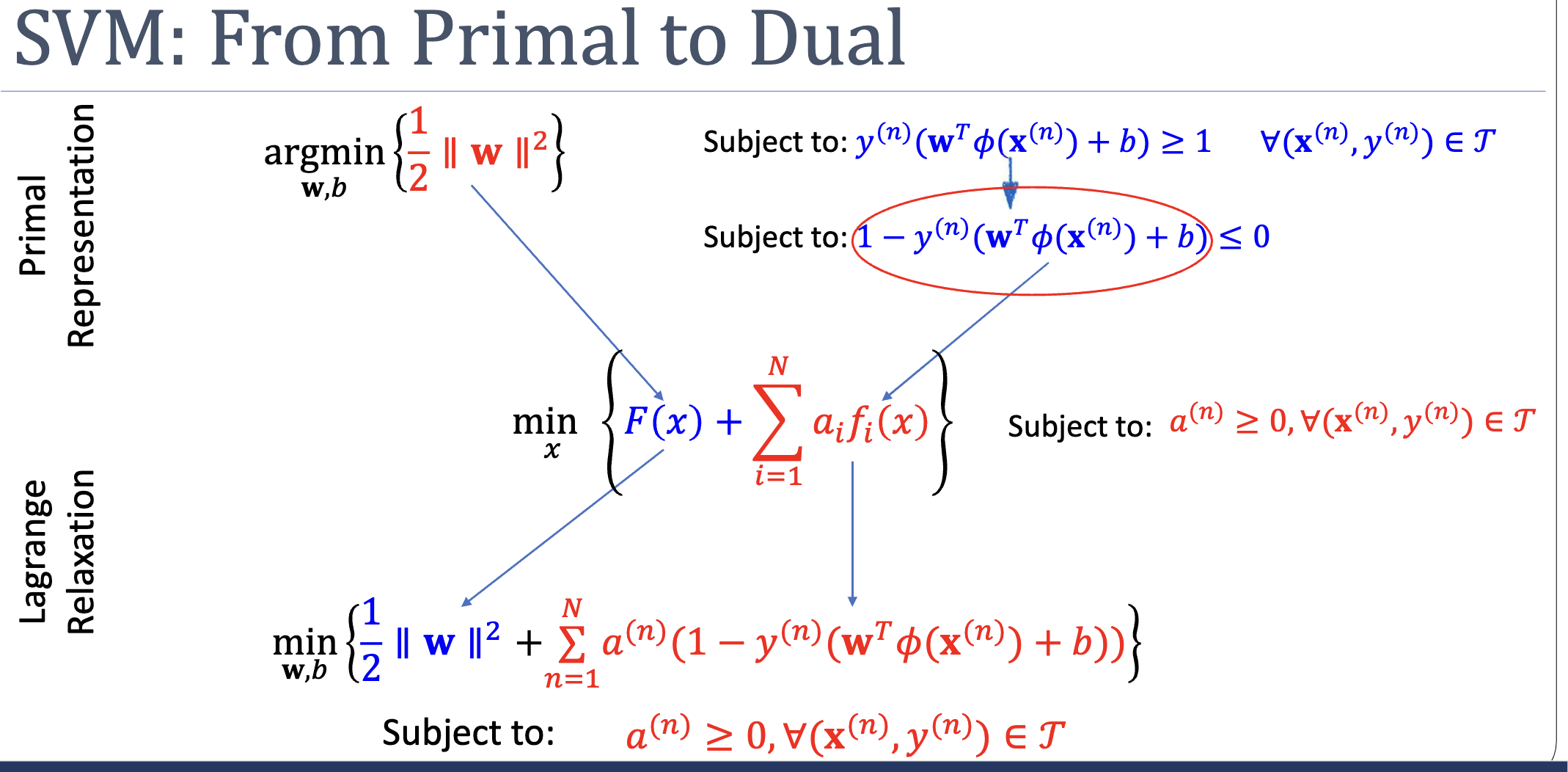
Setting up the minimax (and equivalently the dual maxmin) gives the saddle-point form whose inner min has closed-form solutions for and the constraint :

Active Recall
Why does the inner in the minimax formulation reproduce the original constraint exactly?
Because the multipliers are unbounded from above. If a constraint is violated (), the max wants to drive to make the penalty arbitrarily large — the outer min then refuses to land on any infeasible . If a constraint is satisfied (), the max wants to avoid making smaller than . Either way, the minimax recovers the original primal: on the feasible set, outside it.
Strong duality fails for non-convex problems. What can the dual still tell us?
Weak duality holds unconditionally — the dual is always a lower bound on the primal. Even when there’s a duality gap, the dual gives a certificate of optimality (the primal can’t do better than the dual value). For non-convex problems where the primal is intractable, solving the dual can still yield useful bounds on how good a heuristic primal solution is.
Related
- kkt-conditions — the necessary and sufficient optimality conditions that primal/dual solutions must jointly satisfy
- support-vector-machine — the canonical ML use case
- kernel-trick — what becomes possible after going to the dual
- quadratic-programming — the structural form SVM lives in (quadratic objective, linear constraints)