The simplest artificial neural network: a single neuron that computes a weighted sum of its inputs, adds a bias, and passes the result through an activation function.
Definition
A perceptron (also called a McCulloch-Pitts neuron) takes a vector of inputs , multiplies each by a learned weight , adds a bias term , and applies the sign function to give a single output (i.e. draws a hyperplane):
where
The learnable parameters are the weight vector and the scalar bias .
Intuition: the recipe analogy
Think of the inputs as ingredients and the weights as how much of each ingredient goes into the dish. The neuron computes the weighted sum — mixing all ingredients in proportion — and then the activation function acts like the chef’s judgment: given the mixture, does this dish pass the threshold or not?
| Component | Recipe analogy |
|---|---|
| Inputs | Ingredients |
| Weights | Quantities of each ingredient |
| Weighted sum | The combined mixture |
| Bias | A baseline added regardless of ingredients (e.g. salt always goes in) |
| Activation / sign function | The chef’s decision: is the dish ready? |
Two things to watch out for:
- Weights can be negative — interpret these as ingredients that suppress the output rather than contribute to it.
- In deeper networks the “ingredients” fed into layer 2 are already-processed outputs from layer 1, not raw features, so the analogy becomes recursive.
Biological analogy
The perceptron is a crude model of a biological neuron:
- Dendrites receive signals from other neurons inputs
- Synaptic strengths determine how much each signal matters weights
- Cell body (soma) aggregates the incoming signals weighted sum
- Axon fires if the aggregated signal exceeds a threshold sign function
Real neurons are far more complex, but this abstraction captures the essential idea: combine inputs, threshold, produce an output.
Classification mode
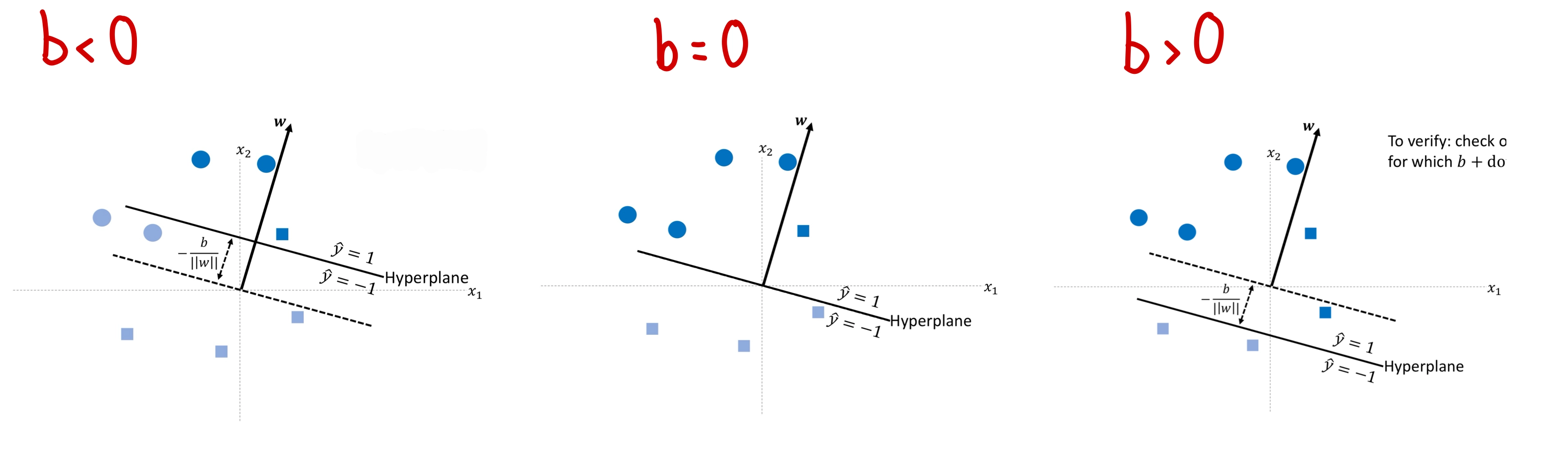
With the sign activation, the perceptron is a binary classifier. It assigns every input to one of two classes ( or ) by checking which side of a decision boundary the point falls on. The boundary is the hyperplane .
The dot-product measures signed distance from the input to the hyperplane (scaled by ). Points on the same side as get classified as ; points on the opposite side get . In other words the dot product gives us an idea of how far a point is from the decision boundary i.e. which side of the boundary it is on.
What the parameters control:
| Parameter | Role |
|---|---|
| Orientation of the decision boundary (boundary is perpendicular to ) | |
| Position of the boundary (shifts it along from the origin) |
A negative shifts the boundary in the direction of ; a positive shifts it against . When , the hyperplane passes through the origin.
Regression mode
Remove the sign function and the same neuron becomes a linear regressor:
This is standard linear regression ( in 1D). The weight is the slope along dimension and is the intercept. Instead of splitting space into two half-spaces, the neuron now fits a line (or hyperplane) through the data.
Hard vs soft perceptron
The version above — with the sign activation — is called a hard perceptron. The output flips abruptly from to at the decision boundary: the decision is “hard”. A soft perceptron replaces the sign with a smooth activation like the sigmoid function:
Output transitions smoothly through the boundary instead of stepping; the decision is “soft”, and the value can be read as a probability .
| Hard perceptron | Soft perceptron | |
|---|---|---|
| Activation | sign | sigmoid (or tanh, ReLU, …) |
| Output | ||
| Transition at boundary | Step | Smooth S-curve |
| Differentiable? | No — derivative is 0 almost everywhere, undefined at 0 | Yes — derivative is positive and well-defined |
| Trainable by gradient descent? | No — , parameters never update | Yes |
The whole distinction reduces to one property: differentiability. The hard perceptron’s sign function has derivative zero, so by the chain rule the loss gradient collapses to the zero vector and gradient descent cannot move the parameters. Soft activations have non-zero gradients, so training works. Every other apparent difference (probability interpretation, smooth output, gradient flow through deeper layers) is a downstream consequence of that one fact.
This is why every neuron in a modern neural network is a soft perceptron. “Hard” is the original Rosenblatt-1958 model; “soft” is what we use whenever we actually need to train. See multi-layer-perceptron (built from soft perceptrons) and sigmoid function (the canonical soft activation).
Limitations
A single perceptron can only produce a linear decision boundary. If the data is not linearly separable — for instance, an XOR-like pattern where positive points appear in opposite corners — no single hyperplane can classify it correctly. Solving non-linearly separable problems requires combining multiple perceptrons into layers, leading to multi-layer perceptrons (MLPs) and backpropagation (week 3).
Worked Example
Given and , classify :
- Compute the weighted sum:
- Add bias:
- Apply sign:
So .
For : , so .
Related
- dot-product — the algebraic operation at the heart of the perceptron
- decision boundary — the geometric object the perceptron defines
- loss-function — how we measure whether the perceptron’s parameters are good
Active Recall
What changes when you remove the sign function from a perceptron, and what kind of problem does it now solve?
Without the sign function, the perceptron outputs the raw value — a continuous number rather than . This turns it into a linear regressor that fits a line (or hyperplane) through data, predicting continuous targets like commute time or house price.
A perceptron has and . What does its decision boundary look like geometrically, and which points get classified as ?
The boundary is , i.e. the horizontal line . Points above this line () are classified as ; points below as . The weight vector points straight up, so the boundary is horizontal.
Why can't a single perceptron solve the XOR problem, and what architectural change is needed?
XOR has positive examples at and , and negative examples at and — opposite corners. No single straight line can separate them. You need at least two perceptrons in a first layer (each drawing its own boundary) whose outputs feed into a third perceptron, forming a multi-layer network.
What is the difference between a hard perceptron and a soft perceptron, and which property is the distinction really about?
A hard perceptron uses the sign activation: output is with an abrupt step at the decision boundary. A soft perceptron uses a smooth activation (sigmoid, tanh, ReLU, …): output is a continuous value with a smooth transition. Everything else (probability interpretation, smooth output) follows from the underlying property: differentiability. The hard perceptron’s sign function has derivative zero almost everywhere, so gradient descent collapses to and the parameters never update. The soft version has a non-zero gradient and can actually be trained — which is why every modern neural network neuron is a soft perceptron.
In the biological analogy, what do dendrites, synaptic strengths, and the axon correspond to in the perceptron model?
Dendrites correspond to the inputs (receiving signals from other neurons). Synaptic strengths correspond to the weights (how much each input matters). The axon corresponds to the output (the signal sent onward after the soma aggregates and thresholds).
Compute the output of a perceptron with , for input . Explain the geometric meaning.
. The sign function at gives (by convention, ). Geometrically, the point lies exactly on the decision boundary , which is the line .