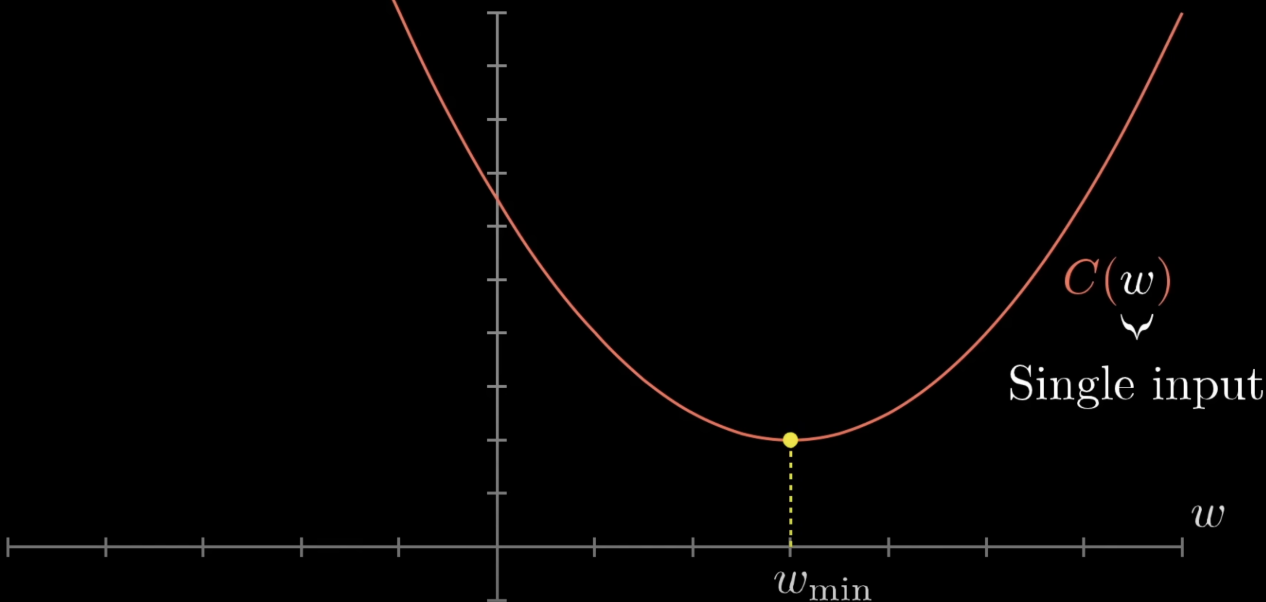
A function is convex if any line segment between two points on its graph lies above (or on) the graph. Convexity is the property that makes optimisation tractable — every local minimum is a global minimum.
Definition
A function is convex if, for all in its domain and :
Geometrically: the chord connecting any two points on the graph never dips below the graph.
 Strict convexity replaces with (for and ), ruling out flat regions.
Strict convexity replaces with (for and ), ruling out flat regions.
A concave function is just the negative of a convex one (chord lies below the graph). Maximising a concave function is the same problem as minimising a convex one.
Why Convexity Matters
The key consequence: for a convex function, every local minimum is a global minimum. If gradient descent converges to a critical point (), that point is the global optimum — no worry about being trapped in a worse local minimum.
For strictly convex functions, the global minimum is also unique (no flat plateaus or multiple equally-good optima).
Tests for Convexity
For univariate, twice-differentiable : is convex iff everywhere. Strictly convex iff everywhere.
For multivariate, twice-differentiable : is convex iff its Hessian is positive semi-definite at every point ( for all ). Strictly convex iff is positive definite (strict inequality for ).
Subgradient test (for non-differentiable convex functions): any subgradient — a linear function that touches the graph at a point and lies below it everywhere — exists at every point in the interior of the domain. If is a subgradient at , then is a global minimum.
Examples
| Function | Convex? | Notes |
|---|---|---|
| Yes (strictly) | ||
| Yes (strictly) | ||
| Yes (strictly) on | ||
| Yes | Convex but not differentiable at 0; subgradient exists | |
| Yes (strictly) | Bowl | |
| No | Curvature flips sign |
Convexity in Machine Learning
The optimisation problems we want to solve are convex if both the loss and any regularisers are convex (and combined with non-negative weights). Convex problems include:
- Linear regression with squared error.
- Logistic regression with cross-entropy loss — strictly convex in .
- Support Vector Machines with hinge loss + L2 regularisation.
- Lasso (linear regression + L1 regularisation).
Non-convex problems include neural networks (the network’s output is a non-convex function of its weights), most clustering objectives (K-means is non-convex), and many latent-variable models.
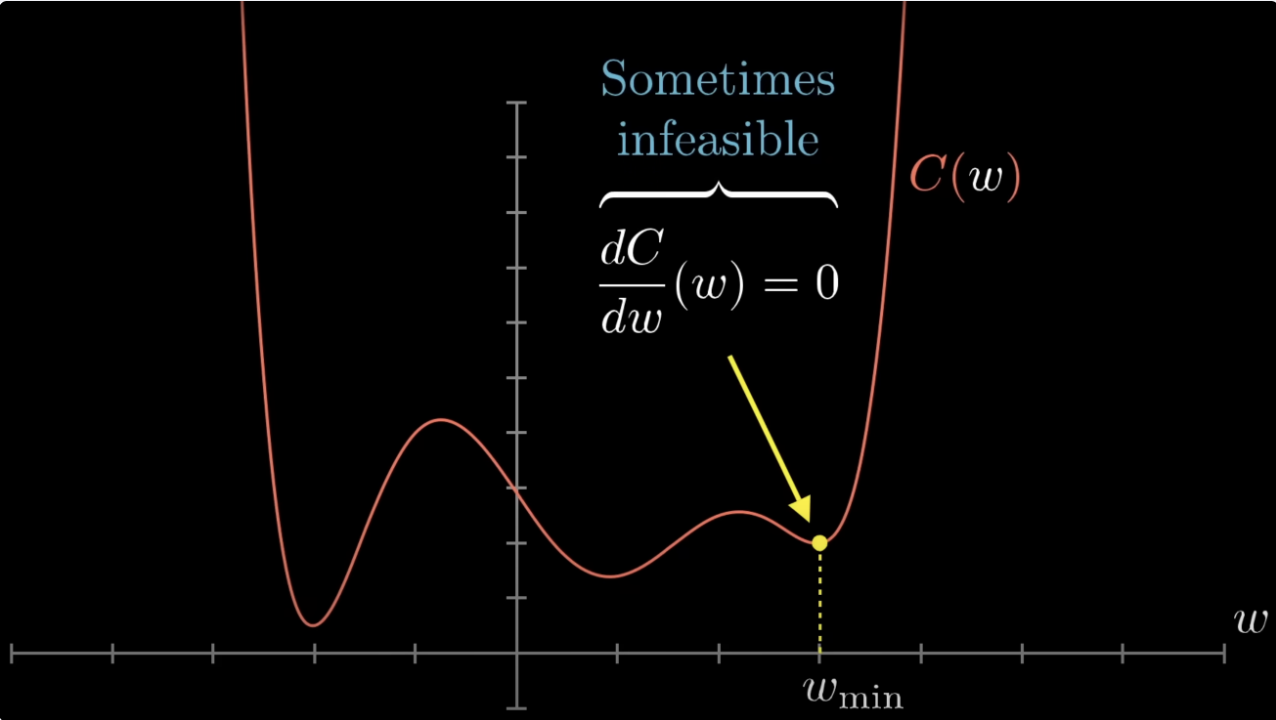
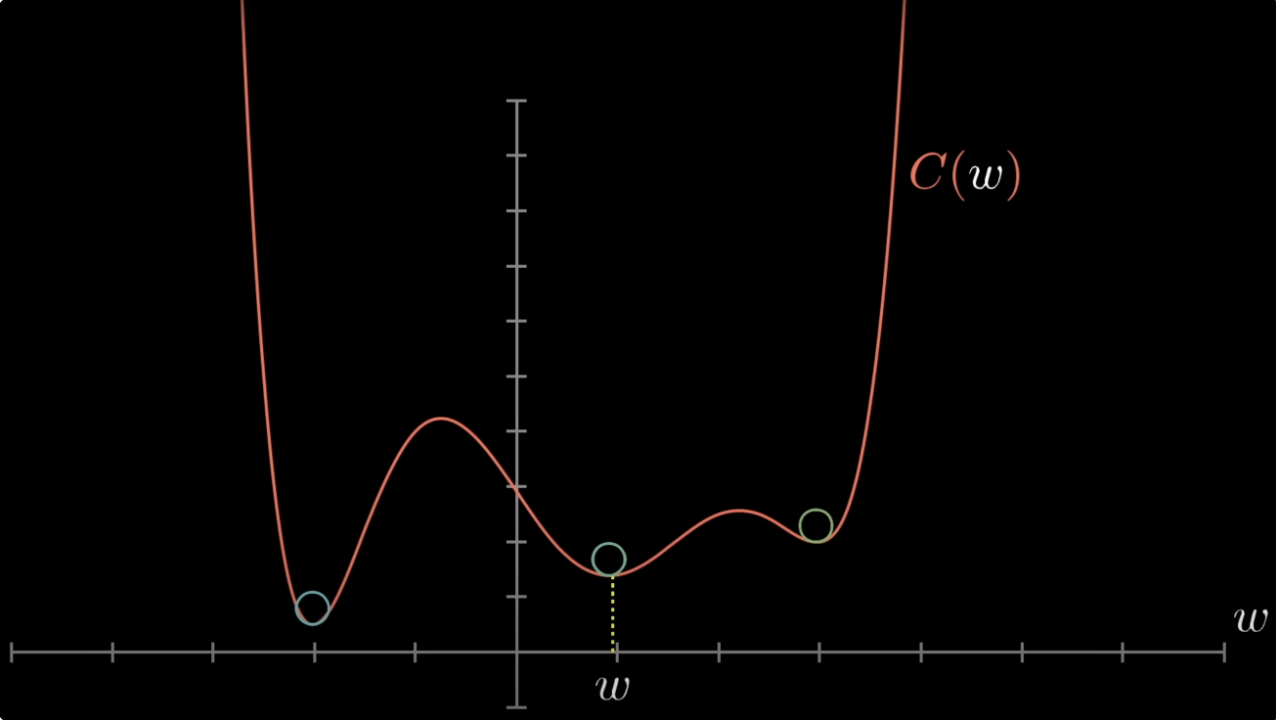
When the problem is convex, gradient descent and Newton-Raphson are guaranteed to find the global optimum (under mild conditions). When it is not, optimisation becomes a heuristic search — gradient descent finds some local minimum, and we hope it’s a good one.
Operations That Preserve Convexity
- Sum of convex functions is convex.
- Maximum of convex functions is convex (e.g., — the ReLU).
- Composition with an affine function: is convex if is.
- Non-negative scaling: is convex for .
These rules let you build complex convex losses from simple convex pieces.
Related
- cross-entropy-loss — strictly convex in , hence has a unique global minimum
- gradient descent — succeeds reliably on convex losses
- newton-raphson-method — guaranteed to descend on (locally) convex regions
- hessian-matrix — positive semi-definite Hessian characterises convexity
Active Recall
Why does convexity make optimisation easy?
For a convex function, every local minimum is a global minimum. So any iterative method that descends (gradient descent, Newton-Raphson) and converges to a critical point is guaranteed to land on the global optimum. There is no risk of getting trapped in a worse local minimum, and no need for expensive techniques like random restarts or simulated annealing.
How can you tell if a twice-differentiable multivariate function is convex?
Check whether its Hessian is positive semi-definite at every point in the domain — i.e., for all and all . For strict convexity, replace with (for ). Equivalently: all eigenvalues of are non-negative (positive for strict convexity).
Is (absolute value) convex? Differentiable? How would gradient-based optimisation handle it?
Yes, it’s convex (the chord between any two points lies above or on the graph). But it’s not differentiable at . Standard gradient descent fails there because there’s no unique gradient. The fix is the subgradient: any line that touches the graph at and lies below it (any slope between and ) qualifies as a subgradient, and subgradient descent uses one to determine the update direction. At , the subgradient exists, signalling that we’re at the global minimum.