A principle for fitting parametric models: choose the parameters that make the observed data most probable. For supervised learning, this turns “find the best ” into a precise optimisation problem.
The Principle
Given a parametric model and a training set drawn i.i.d. from the true distribution, the likelihood of the parameters is the joint probability of the observed labels:
The maximum likelihood estimate is the parameter vector that maximises this:
Intuitively: of all the candidate ‘s, pick the one for which the data we actually saw is the most plausible.

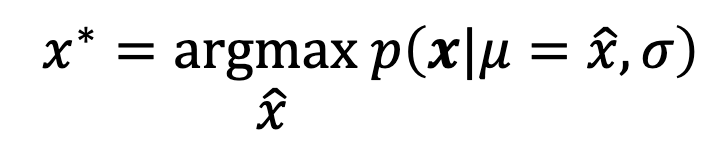
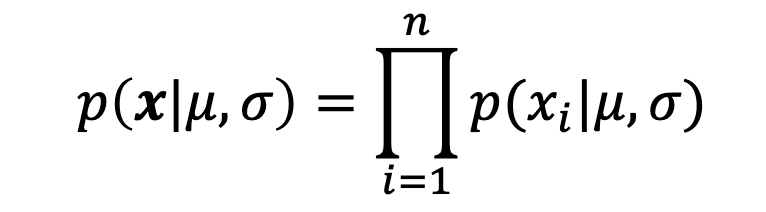


Probability vs Likelihood
The quantity has two readings depending on what is fixed:
| Reading | Fixed | Variable | Question answered |
|---|---|---|---|
| Probability | ”Given these parameters, how likely is this label?” | ||
| Likelihood | ”Given this observed label, how plausible are these parameters?” |
In MLE, the data is observed and fixed; we vary to find the best fit. The mathematical formula is identical; only the interpretation flips.
Why Take the Log?
Working directly with the product is awkward for two reasons:
- Numerical underflow. Multiplying probabilities (each ) gives an absurdly small number that floating-point arithmetic represents as zero.
- Calculus on products is messy. Differentiating a product of terms via the product rule blows up; differentiating a sum of terms is term-by-term.
The fix is the monotonic logarithm. Since is strictly increasing, . The log-likelihood turns the product into a sum:
Convention also prefers minimisation, so we negate to get the negative log-likelihood, which serves as a loss function:
MLE for Logistic Regression
For logistic-regression, and . A single likelihood term, written compactly using the binary label, is:
(When this reduces to ; when it reduces to .) Plugging into the log-likelihood and negating gives the cross-entropy-loss:
So maximum likelihood and cross-entropy minimisation are the same problem for logistic regression — they differ only by a sign and a logarithm. Whichever lens you use, the optimal is the same.
MLE Is the Source of Standard Loss Functions
A subtle point worth flagging: the loss function we minimise is not arbitrary — it falls out of MLE once you commit to a likelihood model. Different probabilistic assumptions yield different “standard” losses:
| Likelihood model | becomes | Standard name |
|---|---|---|
| Bernoulli () | Binary cross-entropy-loss | |
| Categorical ( one of classes) | Multi-class cross-entropy | |
| Gaussian noise (, ) | Squared error / MSE | |
| Laplace noise () | $\tfrac{1}{b} | y - f(\mathbf{x}, \mathbf{w}) |
| Poisson () | Poisson loss |
The squared-error loss for linear regression isn’t a heuristic choice — it’s the negative log-likelihood under a Gaussian-noise model. The cross-entropy loss for logistic regression isn’t a heuristic — it’s the negative log-likelihood under a Bernoulli model. The principle is one (MLE); the loss is whatever the assumed likelihood produces.
This generality is why MLE shows up everywhere in modern ML. Picking a loss function is, implicitly, picking a noise model.
When Does MLE Work?
MLE has good theoretical properties — it’s consistent (recovers the true parameters in the infinite-data limit) and asymptotically efficient (achieves the lowest possible variance among unbiased estimators) under mild conditions.
It can fail when:
- The model is misspecified (the true distribution isn’t in the parametric family).
- Data is scarce relative to the number of parameters (MLE overfits).
- The likelihood has multiple maxima (in non-convex models like neural networks).
For logistic regression, the negative log-likelihood is strictly convex in , so MLE has a unique solution and any optimiser that converges to a critical point converges to it.
Related
- cross-entropy-loss — the negative log-likelihood for logistic regression
- logistic-regression — the model whose parameters MLE finds
- gradient descent — one way to actually solve the MLE optimisation
- supervised-learning — the broader framework MLE lives within
Active Recall
A model assigns probabilities to the correct labels of five training examples. Compute the likelihood and the negative log-likelihood. Which would you rather work with numerically, and why?
Likelihood: . Negative log-likelihood: . The log version is preferable: a sum of moderate numbers, rather than a product of values . With thousands of examples, the raw likelihood would underflow to zero; the log-likelihood remains a well-conditioned sum.
Why does maximising likelihood give the same answer as minimising negative log-likelihood?
Two reasons combine. First, is strictly monotonic, so . Second, negation flips max to min: . So . The optimal is invariant.
For binary logistic regression, write the likelihood term for a single training example in a way that handles both and in a single expression.
. When : . When : . The binary label acts as a switch via the exponents.