A discriminative binary classifier that models the log-odds of class membership as a linear combination of features, producing calibrated probabilities via the sigmoid function.
Definition
Logistic regression models the probability of class 1 as:
where is the weight vector (including a bias term paired with a dummy input ) and is the sigmoid function. Despite its name, logistic regression is a classification method, not a regression method.


Odds and the Logit
Before we can write down the model, we need a quantity that lives on the same scale as a linear combination — i.e., something that ranges over .
Odds are a natural intermediate step. The odds of class 1 are the ratio of its probability to the probability of class 0:
Concretely: if and , then — class 1 is about 2.3× more likely than class 0. If , then — a coin flip. If , then — class 0 is more likely. The odds range over : still not the full real line.
Taking the logarithm of the odds gives the logit (log-odds), which maps :
Now we can safely set this equal to the linear combination:
Both sides are unbounded real numbers. Solving for yields the sigmoid:
Why not model directly? Because for any valid probability — logarithm is only unbounded in one direction, so it still can’t match on the positive side. The logit is the fix precisely because it is symmetric and fully unbounded.
Odds Ratio Interpretation
Since , the odds of class 1 are . A unit increase in feature (all else equal) changes the logit by , which multiplies the odds by . This is why the effect of features on odds is multiplicative, not additive.
This gives logistic regression a direct interpretability advantage: each weight tells you exactly how much feature shifts the class-1 odds. A large positive weight means the feature strongly favours class 1; a large negative weight strongly favours class 0.
Hypothesis Set and Classification
The hypothesis set is . Learning means finding the weight vector that best fits the training data.
Classification follows from probability thresholding:
- predict class 1
- predict class 0
The decision boundary is the hyperplane . Points far from this boundary (large ) have probabilities close to 0 or 1 — the model is confident. Points near the boundary () have — the model is uncertain.
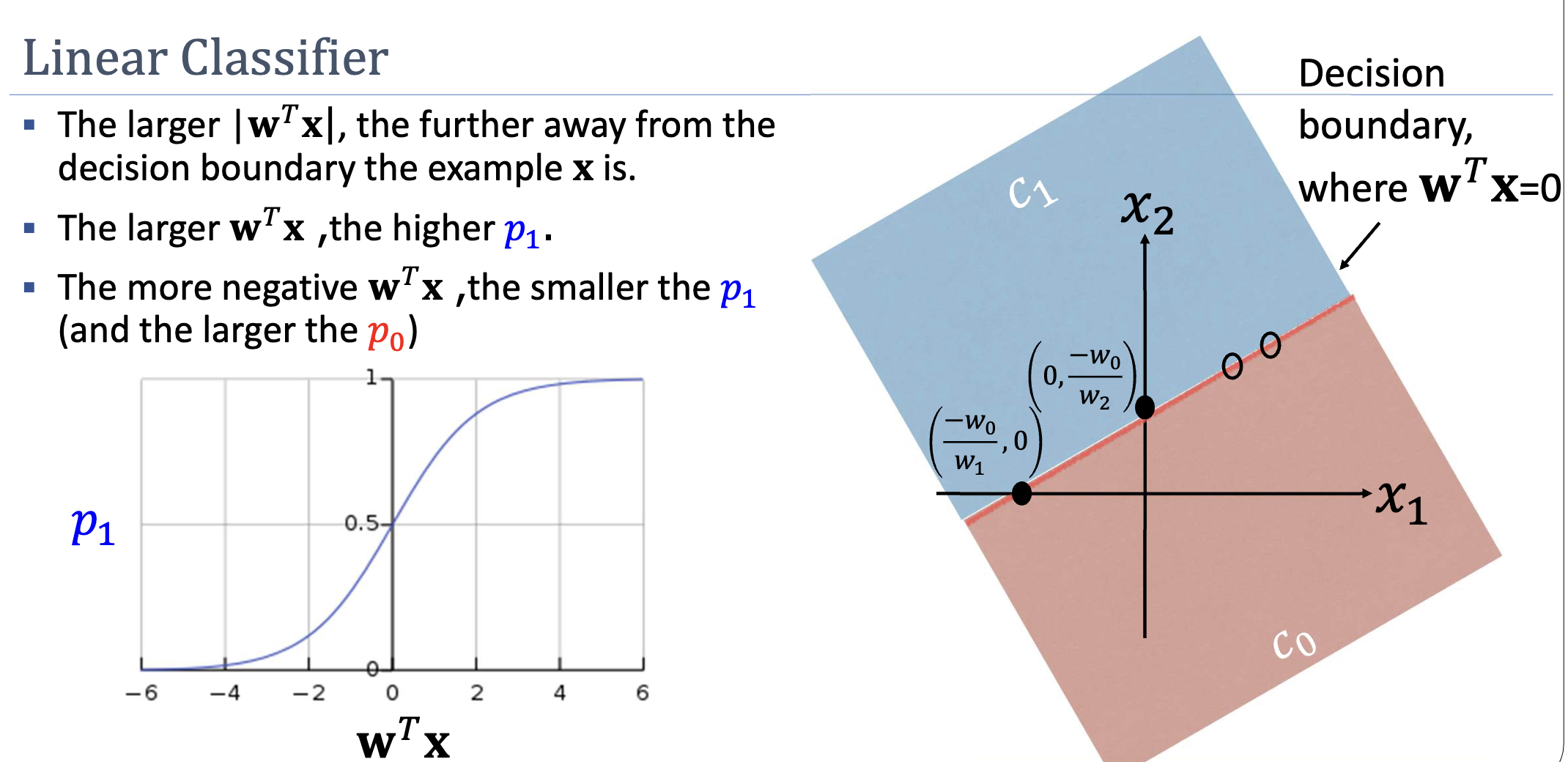
Discriminative Nature
Logistic regression is a discriminative classifier: it directly models without modelling how the features themselves are generated. This contrasts with generative classifiers that model and apply Bayes’ rule.
Worked Example
Setup: Binary classification with 2 input features. Learned weights: . New instance: (where is the dummy variable).
Step 1 — Linear combination:
Step 2 — Classification decision:
Since , predict class 1.
Step 3 — Probability:
The model assigns roughly 89% probability to class 1.

Strengths and Limitations
Strengths:
- Calibrated probabilities, not just labels. is a real probability, useful when downstream decisions depend on confidence — medical risk, fraud scoring, threshold tuning.
- Fast inference. Classification reduces to one dot product and a threshold check; trivially deployable on embedded systems.
- Compact model. Storing is floats. No training data needs to be retained at inference (unlike kNN or SVM, which need support vectors).
- Interpretable coefficients. Each has a direct odds-ratio meaning (); the magnitude indicates feature importance if features are on the same scale and not collinear.
- Extends to multi-class. Softmax regression generalises directly; the optimisation stays convex.
Limitations:
- Linear decision boundary. Without a basis expansion, logistic regression cannot capture curved or disjoint class regions. For non-linearly separable data, a hyperplane in the original space will leave some points misclassified by construction.
- Logistic-form assumption. The model assumes has the specific shape . Real conditional distributions may not — in which case the predicted probabilities are miscalibrated even when the classification accuracy is reasonable.
- Sensitivity to multicollinearity. When features are highly correlated, the estimated weights become unstable: many different vectors give nearly the same predictions, and small changes in the training data swing the weights wildly. Predictions can stay accurate, but coefficient interpretation becomes unreliable.
- Perfect separability is awkward. When the training data is linearly separable, the maximum-likelihood weights are unbounded (they grow to infinity to make saturate). Regularisation (L2 or L1) is the standard fix.
Related
- sigmoid function — the activation that converts logit to probability
- decision boundary — the geometric separator produced by logistic regression
- supervised-learning — the framework logistic regression operates within
- discriminative-vs-generative-models — where logistic regression sits in the taxonomy
- non-linear-transformation — the standard fix for the linear-boundary limitation
Active Recall
Why can't we simply set and call it a day?
The linear combination is unbounded — it can take any value in . Probabilities must lie in . Setting the two equal would produce “probabilities” like or . The logit function bridges this gap: we model the log-odds (which is also unbounded) as , then invert via the sigmoid to recover a valid probability.
Given and , compute , state the predicted class, and calculate .
. Since , predict class 1. .
In a logistic regression model, feature has weight . If increases by 1 unit (all else equal), how do the odds of class 1 change? Why is the change multiplicative, not additive?
The odds are multiplied by — roughly a 65% increase. The relationship is multiplicative because the logit is a log-odds: . Adding to the logit is equivalent to multiplying the odds by , since .
Logistic regression finds a decision boundary, but it doesn't guarantee that the boundary is "good" in any geometric sense. What weakness does this expose, and what later algorithm addresses it?
Logistic regression finds a hyperplane that separates the classes (if the data is linearly separable), but it doesn’t maximize the margin — the distance from the nearest training points to the boundary. A small margin means the classifier is fragile to small perturbations. Support Vector Machines (SVMs) explicitly maximize the margin, producing a more robust boundary.