An extension of the hard-margin SVM that permits training points to sit inside the margin or even on the wrong side of the decision boundary, paying a per-example penalty for each violation. A hyperparameter controls the trade-off between margin width and total violation.
Why Hard-Margin Isn’t Enough
The hard-margin SVM solves:
Two failure modes:
- Non-separable data. If no hyperplane in -space separates the classes, the constraint set is empty and the problem has no feasible solution.
- Overfitting on barely-separable data. Even when the data is separable, a single noisy or mislabelled point near the boundary forces the hyperplane into a contorted position with a tiny margin. With kernels (especially Gaussian), -space is high- or infinite-dimensional, and some separating boundary almost always exists — but it’s the wrong one.
The fix: stop demanding perfect separation. Allow each example a controlled amount of margin violation.
The Primal Formulation
Introduce a slack variable for each training example, relaxing the margin constraint:
Penalise total slack in the objective:
Three things changed from hard-margin:
- The constraint right-hand side is now instead of — points can violate the margin by an amount .
- The objective gains — total violation is penalised.
- The optimisation now has extra variables ().
The margin is now simply : there is no longer a “closest training point” definition because some points might be inside the margin.
The Hyperparameter
trades off margin width against violation tolerance:
| Regime | Behaviour | Risk |
|---|---|---|
| Slacks heavily penalised; recovers hard-margin behaviour | Overfit, especially with high-capacity kernels | |
| Large | Few/small violations; narrow margin | Overfit, may not generalise |
| Small | Many violations allowed; wide margin | Underfit, may misclassify too aggressively |
| Slack is free; margin maximised at all costs | Boundary collapses (any classification works) |
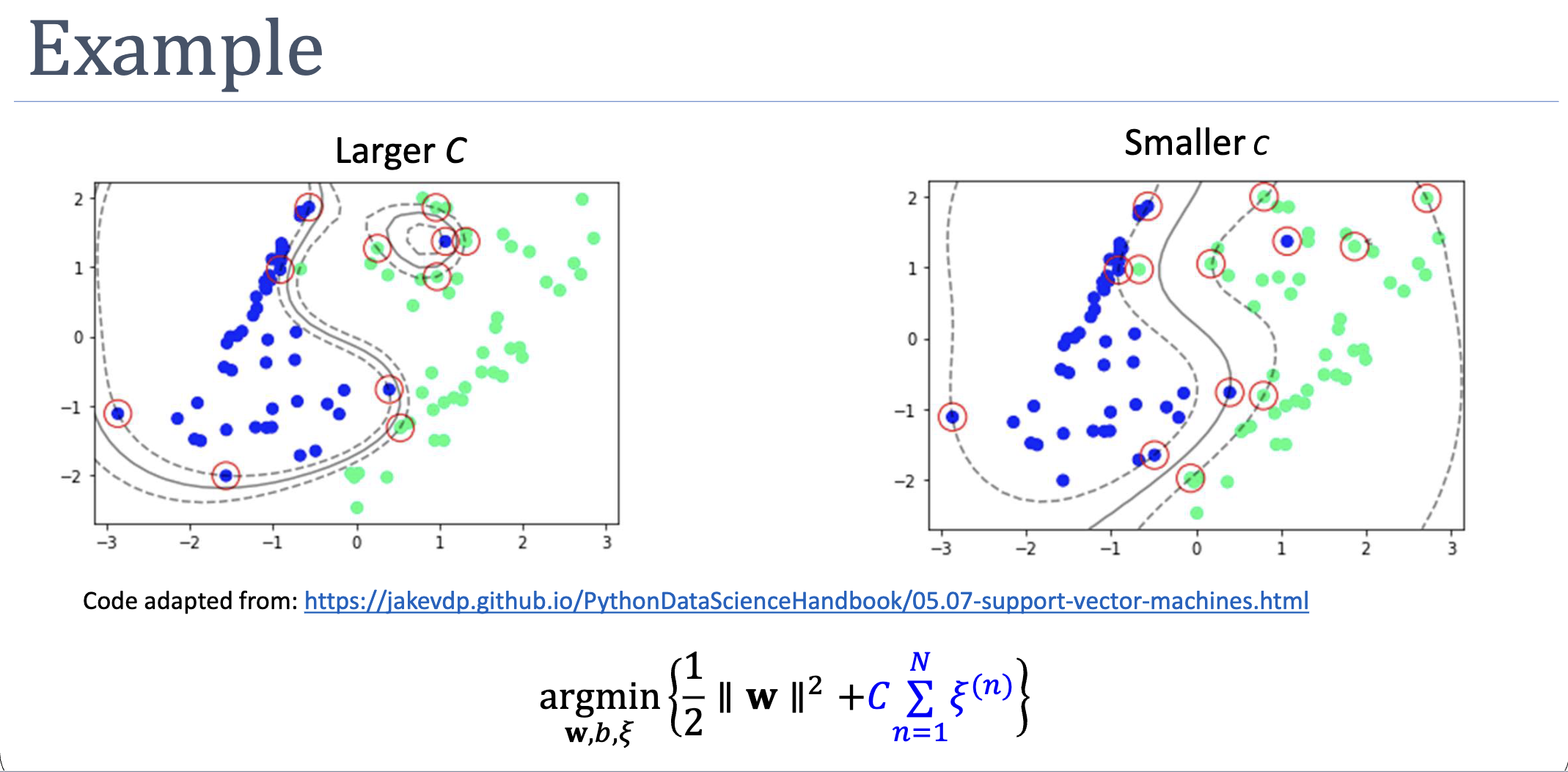
Set via cross-validation. The sklearn SVC default is .
The Dual Formulation
Repeat the Lagrangian / KKT machinery from week 4, this time with two sets of multipliers — for the margin constraint and for :
Setting partials to zero:
- — same as hard-margin.
- — same as hard-margin.
- — new.
Combining with gives the box constraint:
Substituting back, and vanish entirely from the objective — and we get exactly the same dual as hard-margin, but with now upper-bounded by :
subject to and .
The kernel trick still applies — only inner products appear. The dual is almost identical to the hard-margin one. The single difference, , captures the entire effect of the slack relaxation.
KKT Conditions and Support Vector Categories
The complementary slackness conditions for soft-margin SVM are:
These partition training points into three categories based on the value of :
| Type | Geometric position | ||
|---|---|---|---|
| Not a support vector | Strictly outside margin envelope, satisfies | ||
| Margin support vector | Exactly on the margin: | ||
| Bound (clipped) support vector | On margin (), inside margin (), on decision boundary (), or misclassified () |
Why pins the point exactly on the margin
If then , so the second complementary-slackness condition forces . And forces the first condition’s bracket to vanish: , i.e., . The point sits exactly on the margin.
The support-vector population in soft-margin SVM is larger than in hard-margin: every margin-violating example contributes (), in addition to the on-margin ones. Sparsity weakens but is preserved — examples comfortably outside the margin still have .
Predictions
Identical in form to the hard-margin dual:
For , average over the margin support vectors only (those with , where exactly):
where . Don’t use bound support vectors () — their in general, so they’d give wrong values for .
What Could Go Wrong
- Wrong . Too small and the model underfits (everything gets absorbed into slack); too large and we’re back to overfitting via hard-margin behaviour. Always cross-validate.
- No margin support vectors. If every support vector is at , the formula above for has no inputs. In practice this is rare but possible; pick any of them and accept the resulting (or add small regularisation).
- Unscaled features. Same as hard-margin — kernels depend on or . Standardise before training.
How It’s Solved
The soft-margin dual is a convex QP with variables and a linear equality constraint plus box constraints — solvable in principle by off-the-shelf QP solvers, but memory and time make this prohibitive for large . The standard approach is Sequential Minimal Optimization (SMO), which decomposes into two-variable subproblems each solvable analytically.
Connections
- Builds on support-vector-machine — relaxes the hard-margin constraint without changing the dual structure.
- Uses slack-variables — the per-example penalty mechanism.
- Solved by sequential-minimal-optimization — analytic two-multiplier updates.
- Complements kernel-trick — kernels handle non-linearity; slack handles non-separability. In practice you nearly always combine them: RBF kernel + soft margin is the default
SVC.