The algorithm that makes training deep networks tractable. Gradient descent answers “what do we do with ?”; backpropagation answers “how do we compute efficiently, for every parameter, in a network with millions of them?”
What problem it solves
gradient descent needs to update weights. For a single perceptron, computing each by hand is easy. For an MLP with three hidden layers and 36 weights, it’s tedious. For a real network with millions or billions of parameters, naive derivative computation would be:
- Too hard by hand — you can’t plausibly write down a closed-form expression for every parameter’s gradient.
- Computationally wasteful — many intermediate derivatives (e.g. ) appear inside the chain-rule expressions for multiple parameters. Recomputing them is redundant.
Backpropagation solves both at once. It walks the computation-graph representing the network and computes all parameter gradients in two passes.
Simple picture: backprop in the kitchen
A gentler way in, building on the chef analogy from multi-layer-perceptron: the forward pass took ingredients through layer after layer of chefs and ended with a final dish . The customer compares that dish to what they actually wanted () and lodges a single complaint score — the loss.
Backpropagation is the procedure that turns that one complaint into a personalised correction for every chef’s recipe in the kitchen. It answers one question:
Whose recipe should change, in which direction, and by how much?
Each chef has three knobs
When the complaint reaches the output chef, they can do three things:
- Adjust their bias — a uniform seasoning shift.
- Adjust their recipe (weights) — use more of an ingredient that was already strong (high leverage), less of one that hurt the dish.
- Wish the ingredients had been different — they can’t change the ingredients (those came from the previous layer), but they can record a wish list: “I wish ingredient 1 had been higher, ingredient 2 lower.”
The wish list is the gradient signal that travels backwards.
The wish list propagates layer by layer
The previous layer’s chefs are the ones who produced those ingredients. So:
- Each previous-layer chef receives the wish lists from everyone they fed (because their dish became an ingredient for several downstream chefs). They sum the wishes — “collectively, my dish should have been higher (or lower) by this much”.
- Knowing their target, that chef now turns their own three knobs: adjust bias, adjust their recipe, and produce a wish list for the chefs behind them.
- That wish list gets passed back another layer.
Repeat all the way to the input. By the time the recursion terminates, every weight in every chef’s recipe knows exactly how it should change. This collected list of nudges is the gradient — exactly what gradient descent needs.
Why it’s called backpropagation
| Direction | What flows | Why |
|---|---|---|
| Forward (input → output) | Data — ingredients become dishes layer by layer | Compute the prediction |
| Backward (output → input) | Complaint — wish lists propagate through the kitchen in reverse | Tell every chef what to change |
The same kitchen, walked in reverse — hence back-propagation.
Why it’s efficient
Naïve question: “how does this one weight affect the loss?” — would trace a forward path through every downstream chef. With millions of weights, the same paths get retraced over and over.
Backprop’s insight: when the wish list arrives at chef , it already encodes everything downstream of . Each gradient is computed once and reused for every weight that chef owns. The whole walk-back costs work proportional to the number of chefs, not the number of paths.
That’s why training a billion-parameter network is feasible at all.
Intuition: what does a single training example want?
Before the math, here’s the framing that makes backprop click. Take an MLP trained to classify MNIST digits. Show it a hand-drawn “2”. The network’s output layer is 10 neurons (one per digit). At first, the output activations are random — say .
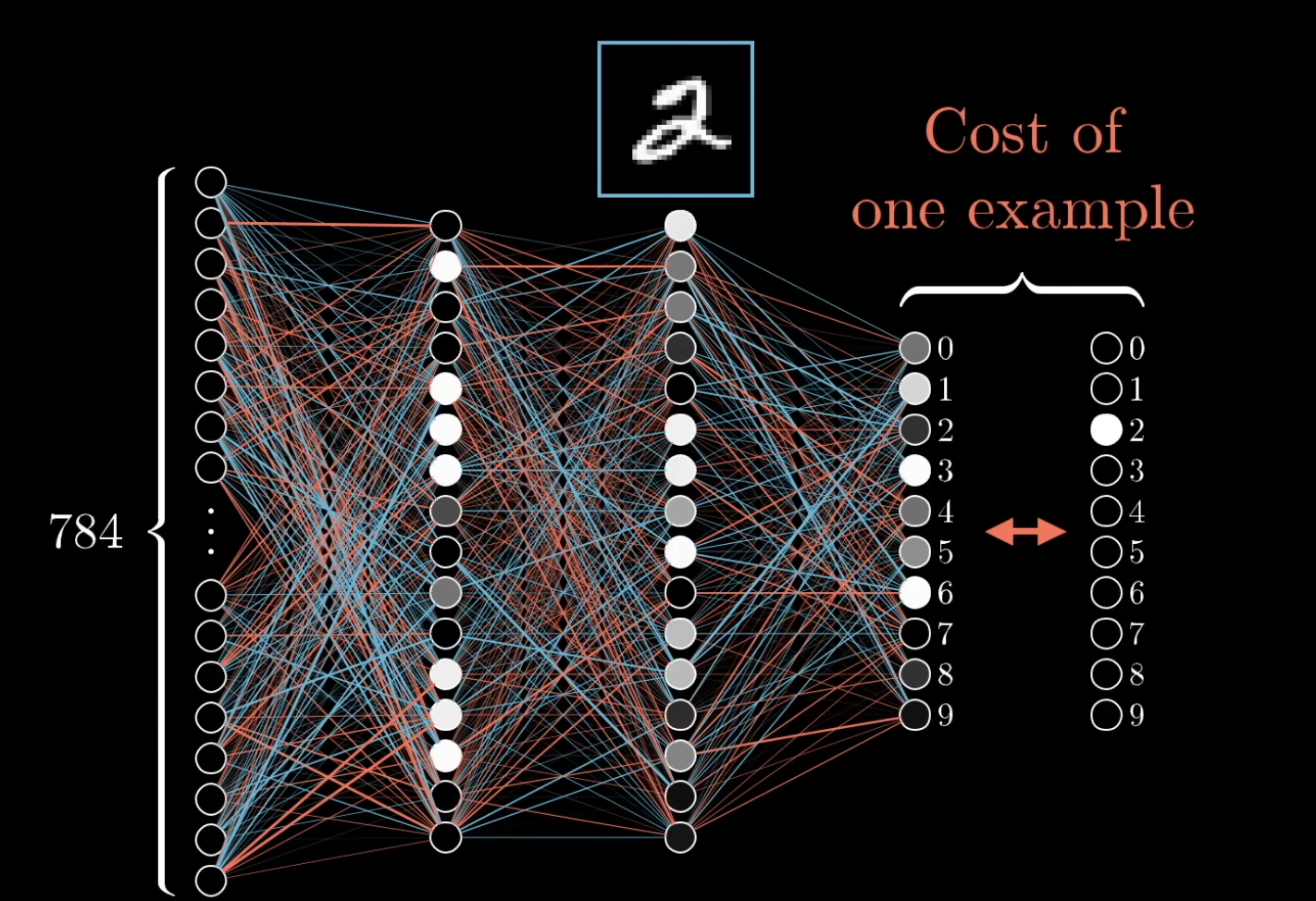
We want the “2” neuron to be high and every other neuron to be low. Each output neuron needs a nudge:
- “2” neuron at 0.2 → nudge up, by a lot.
- “3” neuron at 1.0 → nudge down, by a lot.
- “7” neuron at 0.0 → already low, nudge down only a little.
The size of each nudge is proportional to how far the current activation is from where it should be. Confidently-wrong activations need the biggest pushes; nearly-right ones barely need touching.
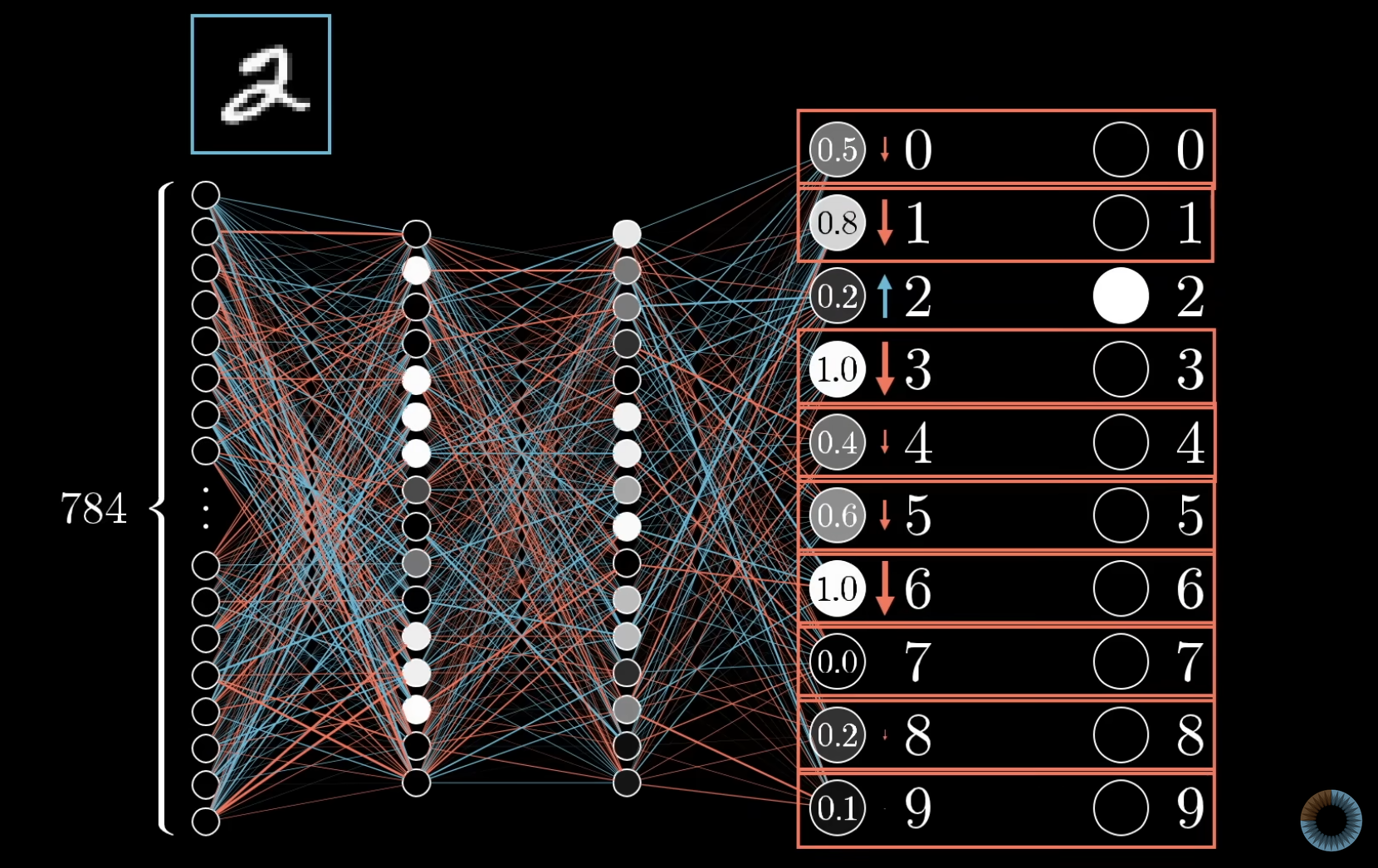
Three avenues to nudge a neuron’s activation
We can’t change activations directly — we can only change weights and biases. For a single output neuron with activation , there are three knobs:
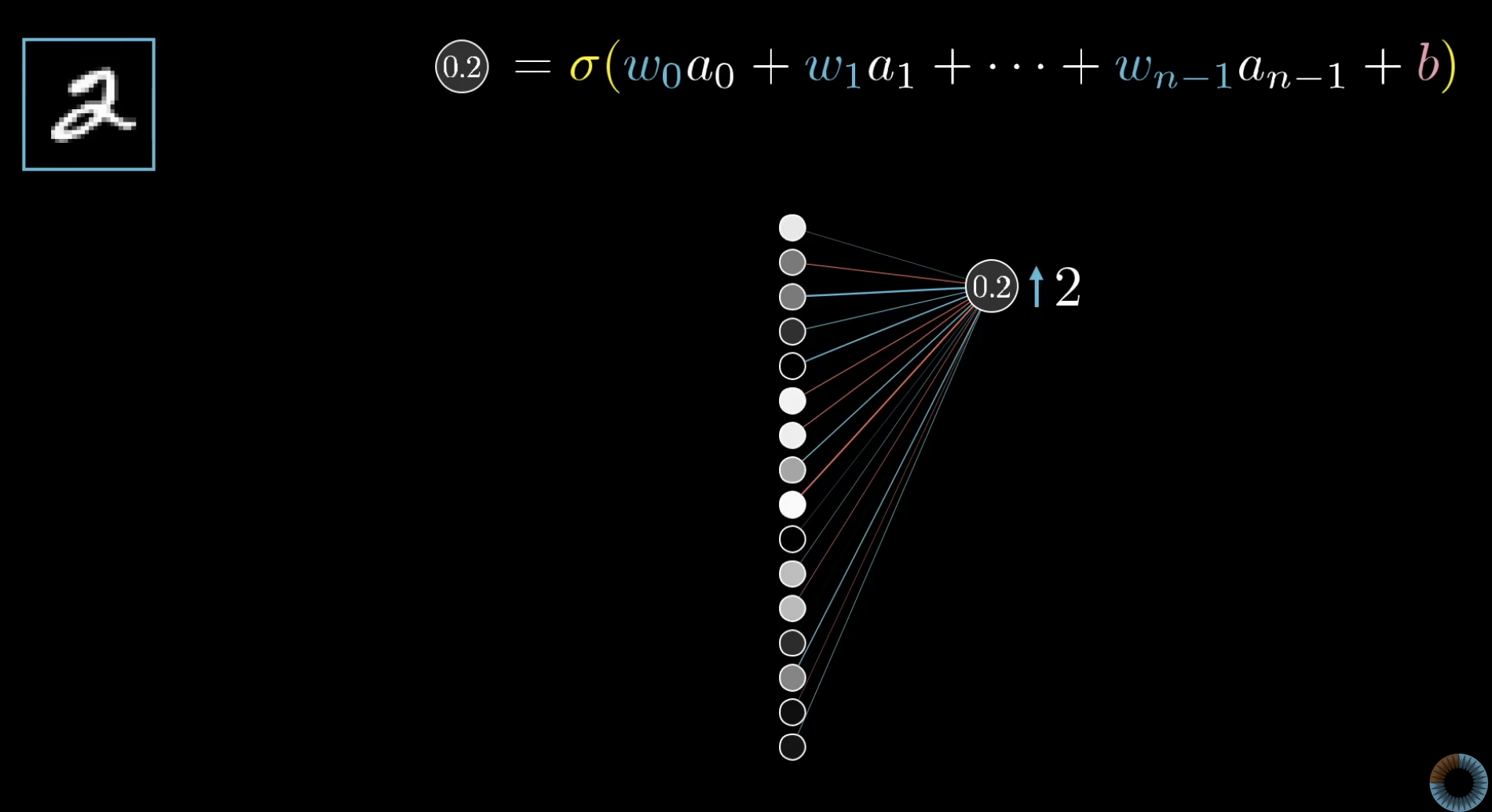
- Increase the bias — a uniform additive nudge to , which pushes up.
- Increase the weights in proportion to the incoming activations — incoming connections from brighter (more active) previous-layer neurons have bigger leverage on , so changing those weights gives more bang for the buck. Connections from dim neurons barely matter.
- Change the activations from the previous layer in proportion to — we can’t directly modify (those are decided by even-earlier weights), but we can record what we wish would do, and propagate that wish backward.
Notice that avenues 2 and 3 are mirror images of each other. Both depend on the product . The connections that matter most are those between active neurons and high-leverage weights.
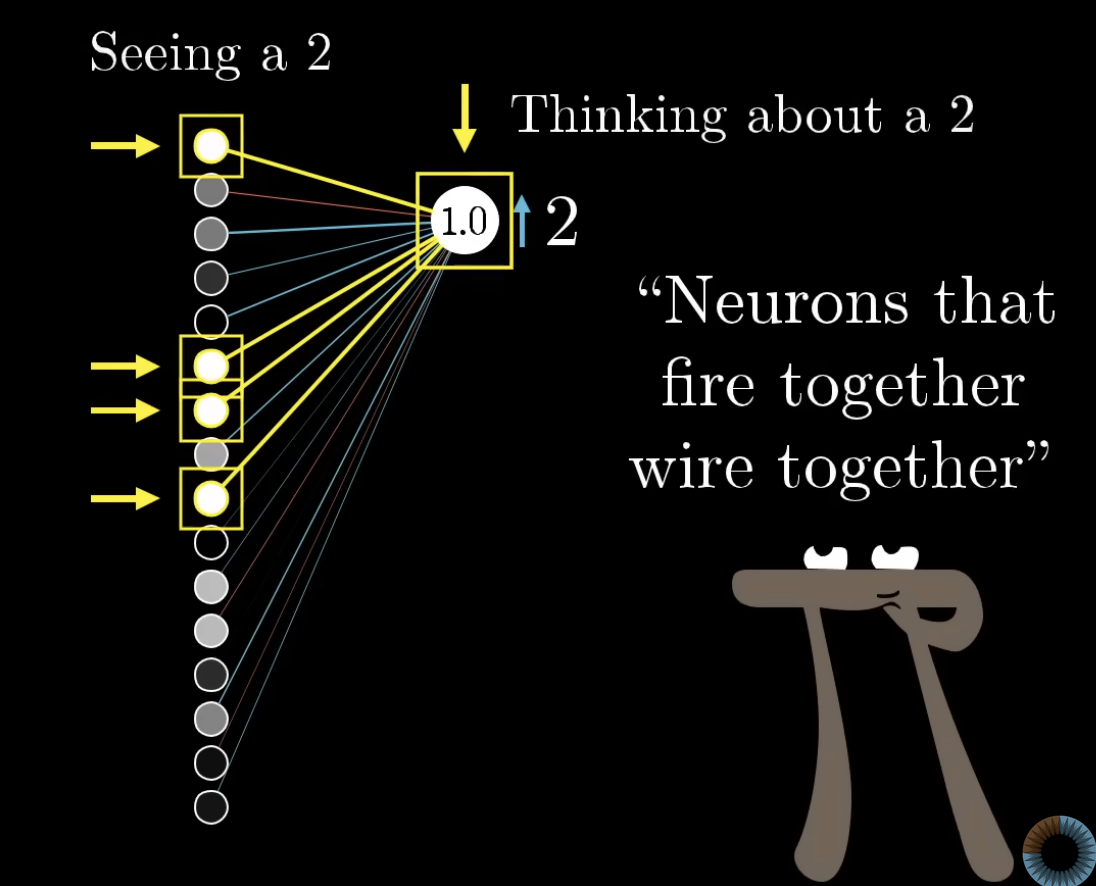
TIP — "Neurons that fire together, wire together"
Avenue 2 says weights from active neurons get strengthened. This mirrors Hebbian theory in neuroscience: when two neurons co-activate during learning, the connection between them strengthens. The biological brain learns roughly the same way an MLP does — by reinforcing connections between neurons that are active when the desired output occurs.
Recursing backward through the network
For each output neuron, we now have a list of desired changes for the previous layer’s activations (avenue 3). But every output neuron has its own list — they each have opinions on what the previous layer should do. Sum these opinions across all output neurons (weighted by the corresponding and by how much each output neuron itself wanted to change). The result: a single list of desired nudges to the previous layer.
That list now becomes the new “what we want” for the previous layer, and we repeat the whole argument one layer further back: this layer’s desires get translated into desired weight/bias changes within it, plus desired activation changes for its previous layer, which we then propagate again.
This is backpropagation. We start at the output, decide what each neuron wants, translate that into local weight/bias updates, and recursively pass the resulting “desires” backward through the network until every parameter has its update.
Averaging across training examples
The above is what one training example wants. If you only used one example, the network would just learn to classify everything as that example’s class. To get a real gradient, run backprop for every training example, record each example’s desired changes, and average them.
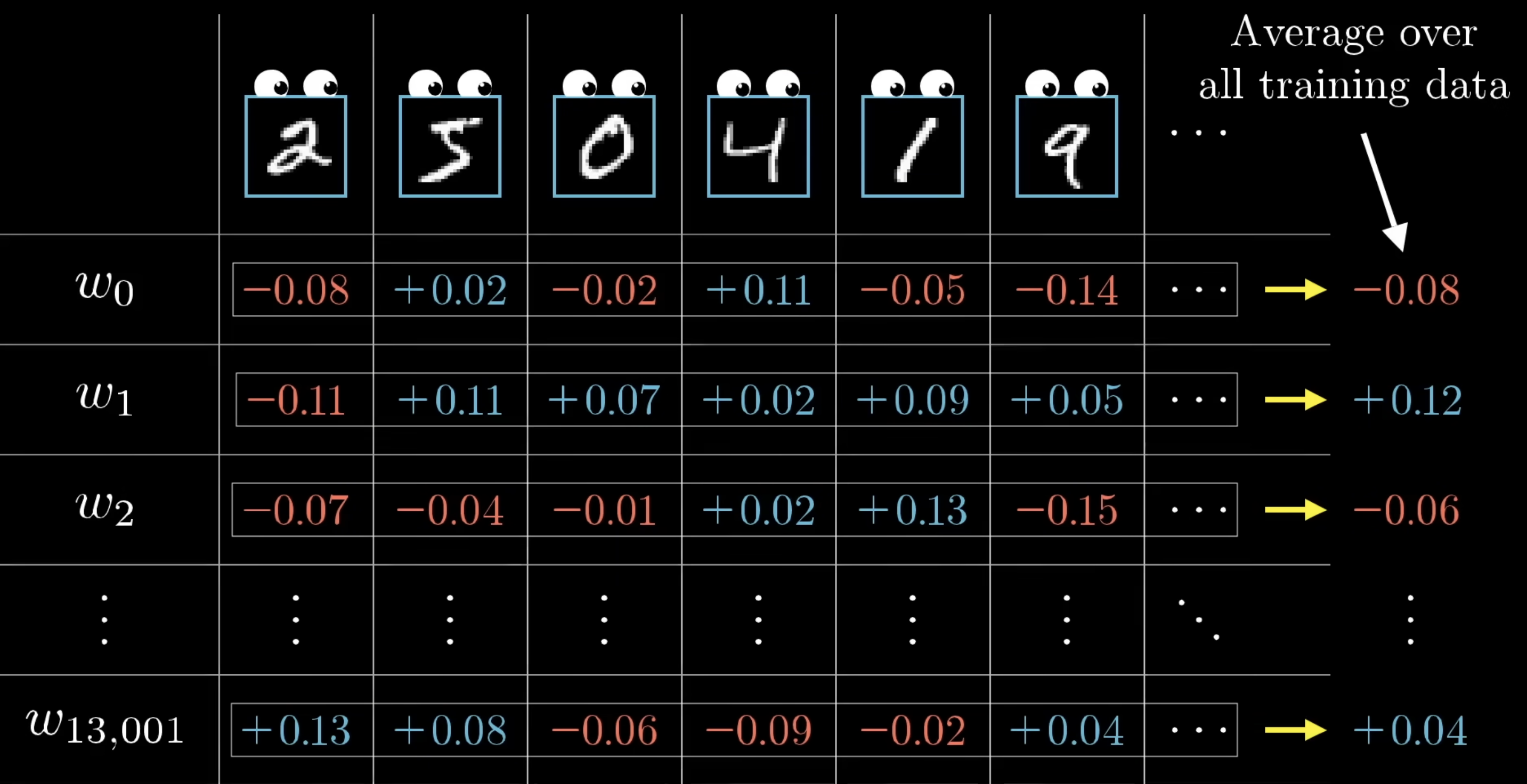
That averaged list of desired changes is — up to a sign — exactly the negative gradient of the cost function. Backpropagation is how we compute this gradient; gradient descent is what uses it.
In practice, averaging over the full training set per step is too slow, so we use mini-batch SGD: average over a random subset of examples, take a step, repeat with a new subset. The gradient estimates are noisier but training is much faster.
What the gradient magnitudes mean
The component of for a particular weight tells you how sensitive the cost is to that weight. If one component is 32 times larger than another, the cost is 32 times more sensitive to changes in the first weight. Backprop doesn’t just tell you “nudge each weight up or down” — it tells you which weights give the most cost reduction per unit of nudging. That’s why gradient descent works as well as it does (see also the non-spatial reading of the gradient in gradient descent).
The mathematical foundation: chain rule
Univariate chain rule
If and , then:
Picture: . The sensitivity of to is the product of the two links in the chain.
Multivariate chain rule
If depends on multiple intermediates that all trace back to — formally with each — then the chain rule sums contributions from every path:
Picture: fans out to , which converge back to . The sensitivity of to accumulates across all paths.
TIP — Why the multivariate case matters for networks
A single weight early in a network often influences many downstream neurons, so the output depends on it through multiple paths. The multivariate chain rule says: to get the true gradient, sum the contribution from every path. This is exactly what backpropagation does automatically.
Chain rule in a computation graph
Generalising to any computation-graph node with successors (the nodes flows into):
The gradient at a node is built from the gradients at its successors. This is the key recursion that backpropagation exploits.
Applying the chain rule to a single neuron’s weight
Concretely, for a weight feeding into the final layer of an MLP, the cost flows through this chain:
with
- — the weighted sum
- — the activation
- — the cost (squared error here)
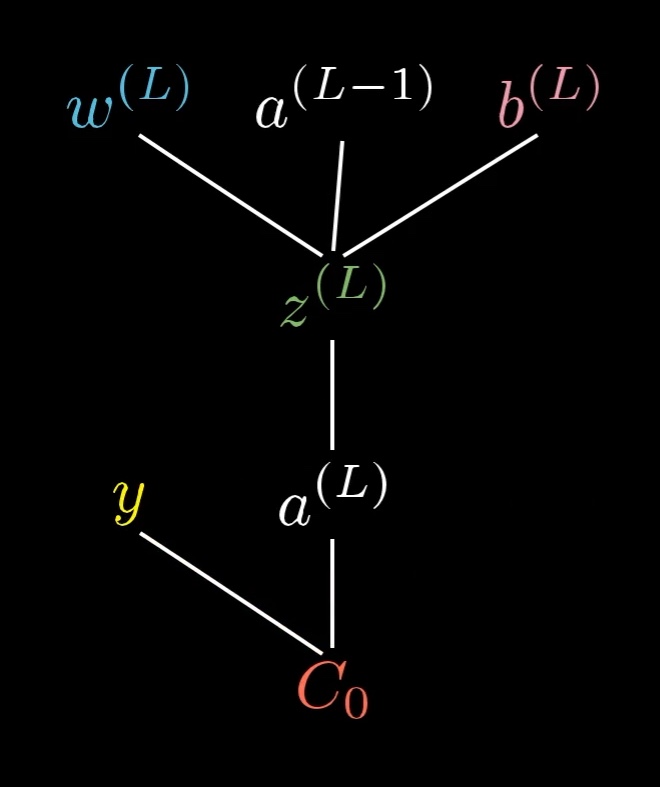
The cost depends on , , and all through the same intermediate — and through one more activation step before reaching .
The chain rule decomposes the gradient into three meaningful pieces:

Read it as a sequence of three nudges: a tiny change in produces a small change in , which produces a small change in , which produces a small change in . Multiply the three sensitivities and you get the total sensitivity of to .
Each piece has a clear interpretation:
- — proportional to how wrong the network is. Big error → big gradient signal.
- — the slope of the activation function at the current pre-activation. If is saturated, this is near zero and the gradient vanishes (a hint of why deep networks have trouble — see future weeks).
- — the activation of the previous neuron. Brighter (more active) previous neurons mean bigger gradient, which is exactly the “fire together, wire together” intuition formalised.
Multiply them together and you have the gradient for one weight. The same recipe applies to every weight in the network — you just chain through more layers.
The bias gradient
Same chain, different last factor. For the bias :
The first two factors are identical to the weight gradient. Only the last one differs: (because enters additively without a multiplier). So is just with the factor stripped out.
The “previous activation” gradient — and the symmetry that makes recursion natural
To recurse one layer back, we need — the cost’s sensitivity to the previous layer’s output. Same chain again:
Compare the weight gradient and the previous-activation gradient side by side:
The two formulas are identical except for the last factor — and the swap is between and . This symmetry comes from being symmetric in and (each is the other’s coefficient). It’s the same principle as Hebbian “fire together, wire together” — the importance of the connection depends on both of them — but now seen from the other side: when you ask how much the cost depends on , the answer is weighted by exactly as how-much-it-depends-on- was weighted by .
Once is known, treat as the “output” of layer and apply the same three-factor recipe to compute , , and . Iterate. Backpropagation is just this same chain rule, applied recursively backwards through the layers.
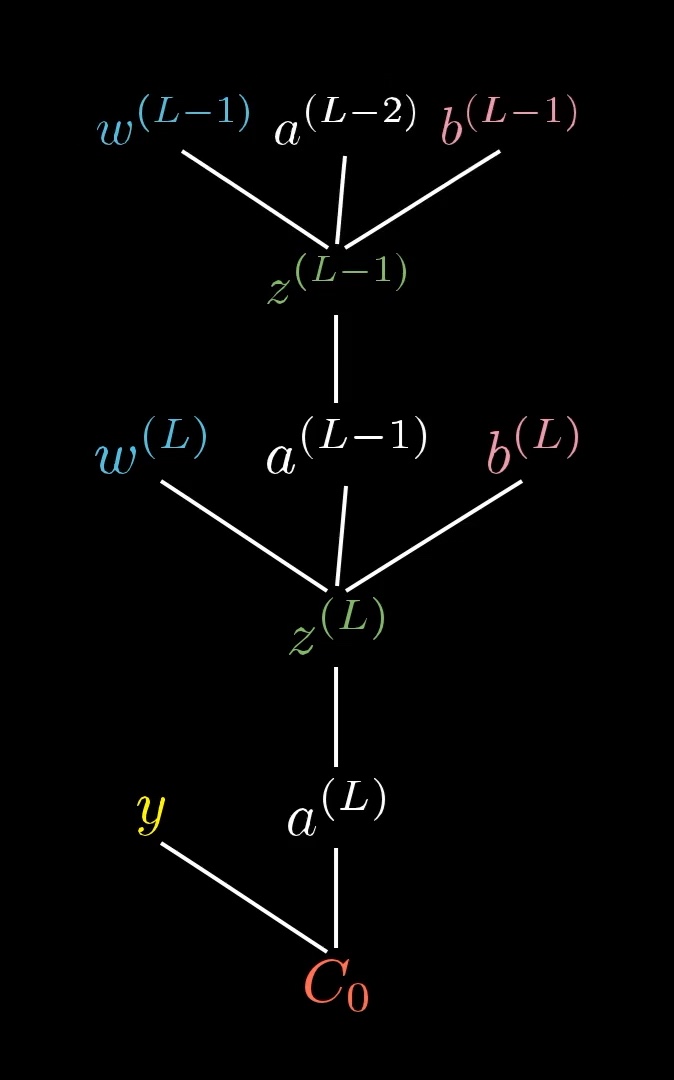
The dependency tree literally extends one layer up: , and now is just an input to the same downstream chain we already analysed. The structure is self-similar — every layer looks like every other layer, only with shifted indices.
All four gradients in one place (one-neuron-per-layer case)

For the simplest network — one neuron per layer, squared-error loss, sigmoid activation, illustrated above as a chain of four neurons (the colour gradient suggests increasing activation from left to right) — all the gradients you ever need are these:
Then recurse: replace with , replace with the just-computed , and repeat. Every gradient in the entire network is some chain of these three patterns.
Multi-path version for hidden activations
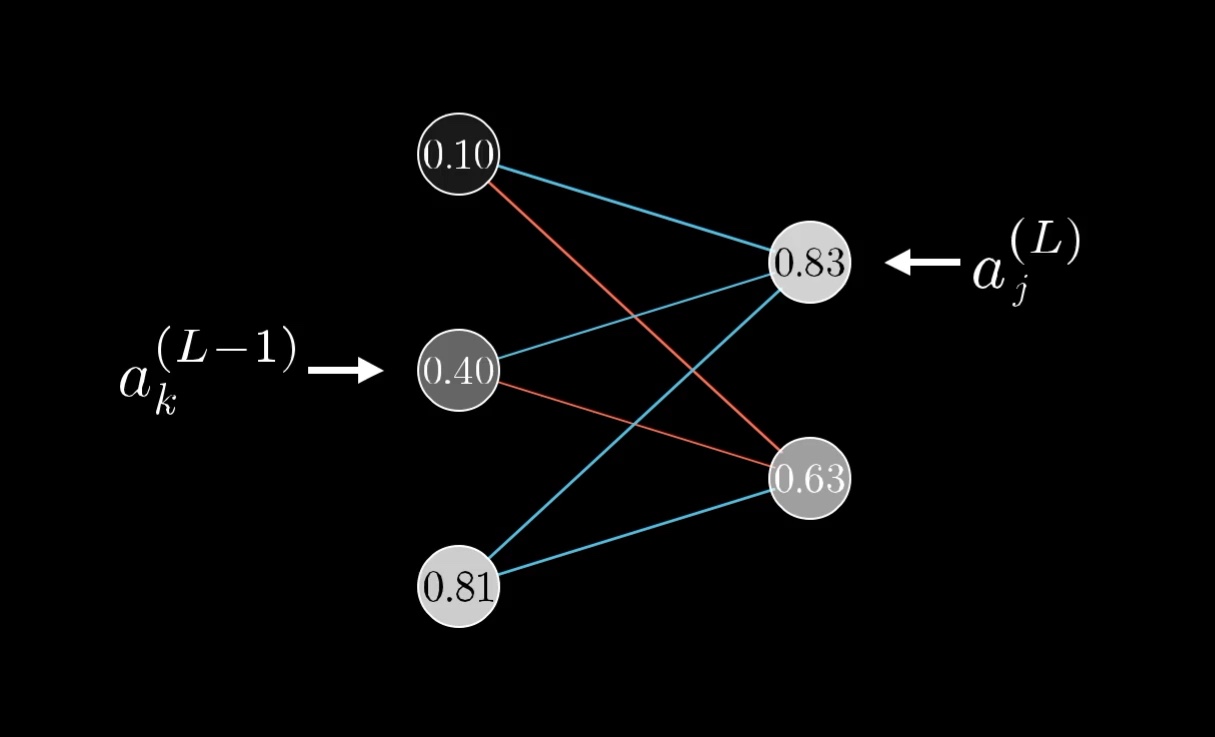
For a hidden activation in layer , the cost depends on it through every neuron in layer . Apply the multivariate chain rule:
Each term in the sum is one path from to through one of the next-layer neurons. The “desires” of all next-layer neurons get added up — exactly as the intuition section described.
Once is known, the same chain-rule trick extends backward to compute and , and so on through every earlier layer. Backpropagation is just this iteration: solve the layer you’re on using gradients from the layer ahead, then move one layer back.
TIP — Multi-neuron layers don't add new ideas, just bookkeeping
The one-neuron-per-layer case has all the conceptual content of backpropagation. When layers are wider:
- Each weight still gets a three-factor gradient — same formula, just decorated with and indices.
- Each previous-layer activation now influences the cost through every next-layer neuron , so its gradient becomes a sum across — that’s the multivariate chain rule from earlier.
- In matrix form, the sums become matrix multiplications and the whole layer’s gradients fit on one line. Implementations use vector/matrix operations to hide the indices.
What does not change: the chain rule, the three pieces, the symmetry between weight and previous-activation gradients, or the recursive backward pass. If you understand the simplest case, you understand backprop. The rest is implementation detail.
The matrix-form summary captures this — the same three-factor pattern, decorated with sums across in the multi-neuron case, and recursively applying to compute :

The boxed term on the right (in 3B1B’s diagram) is the recursion: at the output layer is just from the squared-error loss, and at every other layer it’s a sum across the layer ahead — exactly the multivariate chain rule expressed in indexed form.
The algorithm: forward pass + backward pass
Forward pass
Walk the computation graph from inputs to output. At each node, compute its value from its predecessors’ values and cache it. By the end, you have:
- The output / loss at the final node.
- All intermediate values stored at every node in between.
The forward pass does exactly what inference does — it’s just evaluating the network.
Backward pass
Walk the graph from the output back to the inputs. At each node , compute using the chain rule:
Because we walk backwards, the gradients at each successor are already computed by the time we visit . We just multiply by the local derivative (which uses cached forward-pass values) and sum.
By the end of the backward pass, every parameter node has its gradient , ready to feed into the gradient-descent update.
Worked example:
Take , , .
Forward pass
| Node | Computation | Value |
|---|---|---|
| — | ||
| — | ||
| — | ||
Backward pass
Start from the output. trivially. Move backwards:
| Target | Using | Calculation | Value |
|---|---|---|---|
| , so | |||
| , so | |||
| Two paths: and . Multivariate chain rule: |
Every partial derivative was computed once and reused for each predecessor. That’s the efficiency win.
A second example with a non-linear node:
This time feeds into two downstream paths (the squaring node and the addition node), so even though the graph looks small, the multivariate chain rule applies.
Graph: are inputs; via the squaring node; via the addition node; at the output.
For :
Forward: , , .
Backward:
- — two paths, sum them:
The pattern is identical to the previous example — only difference is one of the local derivatives () involves a forward-pass value, which is why caching forward values matters.
Why “backward”? Why not compute everything forward?
You could compute gradients forward — it’s called forward-mode automatic differentiation, and for each parameter it propagates alongside the forward values. But forward mode computes the gradient with respect to one input at a time. For a network with parameters, you’d need forward passes to get every gradient.
Backward mode (backprop) computes the gradient with respect to one output at a time — and a neural network has one scalar loss output. A single backward pass gets you all parameter gradients. For deep networks with huge and a single loss, backward mode is asymptotically cheaper. That’s why everyone uses it.
Connection to gradient descent
Backpropagation produces . Plug it into the gradient descent update:
and the weights move a small step downhill. Repeat: forward pass → backward pass → update → forward pass → … until convergence (or until you hit the epoch budget). This loop — forward, backward, update — is the training loop for essentially every modern neural network.
One useful framing: at inference time (predicting on new inputs), you only run the forward pass. The backward pass is training-only infrastructure. Once training finishes, you throw away the gradient machinery and keep the learned weights.
Efficiency: the reuse principle
The key insight is that the same intermediate gradients appear in many parameter gradients. In :
- is used to compute both and (part of) .
- is used to compute both and (part of) .
Compute each intermediate gradient once, cache it at the node, reuse everywhere. This turns a naive computation into an efficient one. Without this reuse, training deep networks would be impossible.
Related
- computation-graph — the data structure backprop walks
- gradient descent — the consumer of backprop’s output
- multi-layer-perceptron — the canonical application
- loss-function — the scalar backprop differentiates
Active Recall
What do the forward pass and backward pass each compute, and why does the forward pass happen first?
The forward pass walks the computation graph from inputs to output, computing and caching the value at every intermediate node — ending with the loss at the output. The backward pass then walks backwards, computing at each node by combining gradients from its successors with its local derivative. Forward must happen first because the backward pass uses the cached forward-pass values to evaluate local derivatives (e.g. needs the current value of ).
Apply the multivariate chain rule: for with , , , compute .
Forward: , . Local derivatives: , , , . Multivariate chain rule: .
Why is backpropagation called backpropagation rather than just "automatic differentiation"?
Because it propagates the error signal (gradient of the loss) backwards through the network, from the output layer to the input layer. Each layer receives the gradient from its successor layer, adjusts it by its local derivative, and passes it to its predecessor. The directionality of this gradient flow — from the loss, back to each parameter — is exactly opposite the forward data flow, hence “back-propagation”.
A weight early in a deep network influences many paths to the output. How does backpropagation handle this correctly without repeated computation?
It uses the multivariate chain rule at every node: where the sum is over all successors . Each path’s contribution is accumulated at the node as a sum. The algorithm computes each exactly once (caching it when it visits ) and reuses it for every predecessor — so the total work is proportional to the number of nodes, not the number of paths.
Why do deep learning practitioners prefer backward-mode over forward-mode automatic differentiation for training neural networks?
Forward mode computes in a single pass — good when you have few inputs and many outputs. Backward mode computes in a single pass — good when you have one output (a scalar loss) and many inputs (millions of parameters). Neural network training is exactly the latter case: one scalar loss, many parameters, so a single backward pass gets every parameter’s gradient. Forward mode would need one pass per parameter.
At inference time (using a trained model to predict), which pass(es) do you actually need?
Only the forward pass. The backward pass is used during training to compute gradients for parameter updates. Once training is complete and the weights are fixed, prediction on a new input just involves running the forward pass to compute the output — no gradients, no weight updates.
Backprop on one training example tells you how that single example wants the weights to change. Why is averaging across the training set crucial, and what does the average correspond to mathematically?
Training on a single example would push the network to classify everything as that example’s class — useless. Averaging the per-example desired changes across the full training set produces a balanced update direction that helps every example a little, rather than one example a lot. Mathematically the average is the negative gradient of the loss (which is itself an average over examples), so per-example backprop + averaging = computing . In practice, averaging over mini-batches instead of the full dataset is much faster while still being a good gradient estimate.
Compare and for a one-neuron-per-layer network. What's the same, and what's different?
Both are products of three factors . The first two factors — output error and activation slope — are identical in both. The only difference is the last factor: for the weight gradient, for the previous-activation gradient. The weight gradient is weighted by how active the previous neuron was; the previous-activation gradient is weighted by how strong the connecting weight was. The two formulas are symmetric in and , which is why backprop’s recursion feels so clean — the same three-piece pattern works for every gradient.
For a one-neuron-per-layer network with squared error and sigmoid activation, write down , , and in compact form.
. (same as the weight gradient with the factor stripped — because enters without a multiplier). . The first two factors are shared; only the last one differs based on what we’re differentiating with respect to.
The chain rule decomposition has three factors. What is the practical meaning of each, and which one captures the "fire together, wire together" intuition?
(1) : how wrong the output currently is — big error → big signal. (2) : the activation slope; near zero in saturated regions, where learning slows. (3) : the previous-layer activation. The third term is “fire together, wire together” formalised — when the upstream neuron fires strongly ( is large), the gradient on the connecting weight is large, so that weight gets updated more.